
目录导航
密码生成器 黑客暴力破解密码字典生成器pydictor
下载地址:https://github.com/LandGrey/pydictor
pydictor:一个小巧实用的密码字典生成工具
附6位数字密码字典
6位数字密码字典:
链接: https://pan.baidu.com/s/1b9QZJvZobDfJAQnPtsqGKg
密码: knyn
前言:
Q: 为什么要使用pydictor ?
A: 1.生成密码它总会帮到你
你可以用pydictor生成普通爆破字典、基于网站内容的自定义字典、社会工程学字典等等一系列高级字典;
你可以使用pydictor的内置工具,对字典进行安全删除、合并、去重、合并并去重、高频词筛选,
除此之外,你还可以输入自己的字典,然后使用handler工具,对字典进行各种筛选,编码或加密操作;
2.可定制性强
你可以通过修改多个配置文件、加入自己的字典、选用leet mode 模式、长度选择、
各类字符数量筛选、各类字符种类数筛选、正则表达式筛选,甚至可通过修改
/lib/fun/encode.py文件,自定义加密方法等高级操作;按照API编写标准,在/plugins/文件夹下添加自己的插件脚本,
在/tools/目录下添加自己的工具脚本等。
生成独一无二的高度定制、高效率和复杂字典,生成密码字典的好坏和你的自定义规则、能不能熟练使用pydictor有很大关系;
3.强大灵活的配置解析功能
无需多言,熟练运用后自己体会;
4.兼容性强
不管你是使用的python 2.7版本还是python 3.4 以上版本,pydictor都可以在Windows、Linux 或者是Mac上运行;项目地址: https://github.com/LandGrey/pydictor
欢迎Star、Fork、PR
以下文档来自 pydictor README,可能与更新后的项目文档不一致。
pydictor
一个小巧实用的黑客暴力破解字典建立工具
A useful hacker dictionary builder for a brute-force attack
_______ __ _ _
|_ __ \ | ] (_) / |_
| |__) |_ __ .--.| | __ .---.`| |-' .--. _ .--.
| ___/[ \ [ ]/ /'`' | [ | / /'`\]| | / .'`\ \[ `/'`\]
_| |_ \ '/ / | \__/ | | | | \__. | |,| \__. | | |
|_____| [\_: / '.__.;__][___]'.___.'\__/ '.__.' [___]
\__.'
Email: [email protected]
安装方法:
git clone --depth=1 --branch=master https://www.github.com/landgrey/pydictor.git
cd pydictor/
chmod 755 pydictor.py
python pydictor.py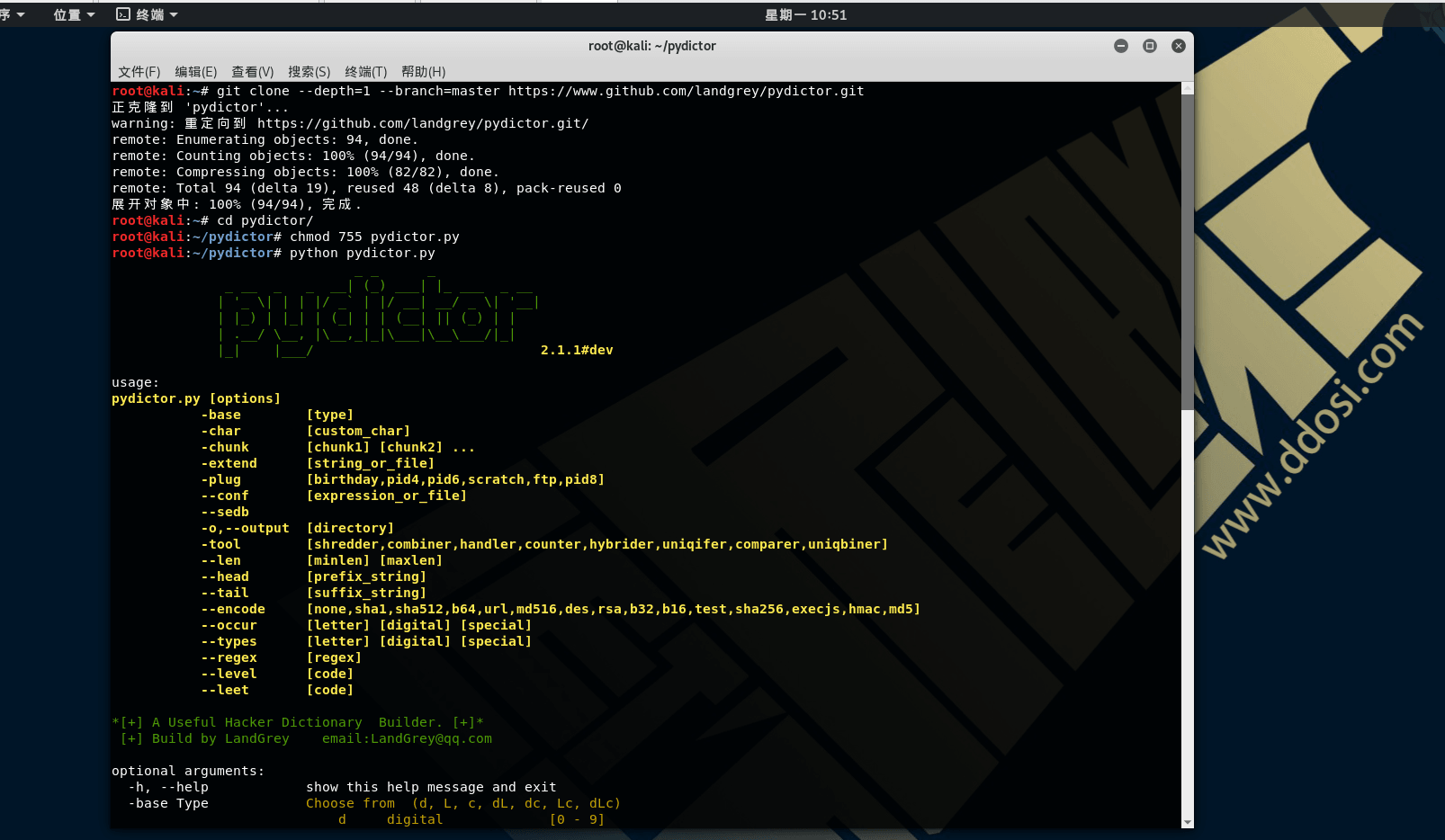
预览:



快速上手:
使用示例文档
插件开发文档
使用pydictor有个窍门: 时刻清楚你想要什么样子的字典.
pydictor可以生成的所有字典的类型及其说明
| 归属 | 类别 | 标识符 | 描述 | 支持功能代号 |
|---|---|---|---|---|
| core | base | C1 | 基础字典 | F1 F2 F3 F4 |
| core | char | C2 | 自定义字符集字典 | F1 F2 F3 F4 |
| core | chunk | C3 | 排列组合字典 | ALL |
| core | conf | C4 | 配置语法生成字典 | ALL |
| core | extend | C5 | 规则扩展字典 | ALL |
| core | sedb | C6 | 社会工程学字典 | ALL |
| tool | combiner | T1 | 字典合并工具 | |
| tool | comparer | T2 | 字典比较相减工具 | ALL |
| tool | counter | T3 | 词频统计工具 | ALL |
| tool | handler | T4 | 筛选处理原有字典工具 | ALL |
| tool | uniqbiner | T5 | 先合并后去重工具 | ALL |
| tool | uniqifer | T6 | 字典去重工具 | ALL |
| tool | hybrider | T7 | 多字典文件组合工具 | F1 F2 F3 F4 |
| plugin | birthday | P1 | 生日日期字典插件 | ALL |
| plugin | ftp | P2 | 关键词生成ftp密码字典插件 | ALL |
| plugin | pid4 | P3 | 身份证后四位字典插件 | ALL |
| plugin | pid6 | P4 | 身份证后六位字典插件 | ALL |
| plugin | pid8 | P5 | 身份证后八位字典插件 | ALL |
| plugin | scratch | P6 | 网页原始关键词字典插件 | ALL |
字典操作功能及说明对照表
| 功能 | 功能代号 | 说明 |
|---|---|---|
| len | F1 | 定义长度范围 |
| head | F2 | 添加前缀 |
| tail | F3 | 添加后缀 |
| encode | F4 | 编码或自定义加密方法 |
| occur | F5 | 字母、数字、特殊字符出现次数范围筛选 |
| types | F6 | 字母、数字、特殊字符各种类数范围筛选 |
| regex | F7 | 正则筛选 |
| level | F8 | 字典级别筛选 |
| leet | F9 | 1337 模式 |
支持的编码或加密方式
| 方式 | 描述 |
|---|---|
| none | 默认方式, 不进行任何编码 |
| b16 | base16 编码 |
| b32 | base32 编码 |
| b64 | base64 编码 |
| des | des 算法, 需要根据情况修改代码 |
| execjs | 执行本地或远程js函数, 需要根据情况修改代码 |
| hmac | hmac 算法, 需要根据情况修改代码 |
| md5 | md5 算法输出32位 |
| md516 | md5 算法输出16位 |
| rsa | rsa 算法 需要根据情况修改代码 |
| sha1 | sha-1 算法 |
| sha256 | sha-256 算法 |
| sha512 | sha-512 算法 |
| url | url 编码 |
| test | 一个自定义编码方法的示例 |
occur 功能
用法 : --occur [字母出现次数的范围] [数字出现次数的范围] [特殊字符出现次数的范围]
示例: --occur ">=4" "<6" "==0"
types 功能
用法 : --types [字母种类的范围] [数字种类的范围] [特殊字符种类的范围]
示例: --types "<=8" "<=4" "=0"
regex 功能
用法 : --regex [正则表达式]
示例: --types "^z.*?g$"
level 功能
用法 : --level [level]
示例: --level 4 /funcfg/extend.conf配置文件中level大于等于4的项目会被启用leet功能
默认置换表
leet字符 = 替换字符,可以修改/funcfg/leet_mode.conf更改替换表
a = 4
b = 6
e = 3
l = 1
i = 1
o = 0
s = 5
模式代码
0 默认模式,全部替换
1 从左至右, 将第一个遇到的leet字符全部替换
2 从右至左, 将第一个遇到的leet字符全部替换
11-19 从左至右, 将第一个遇到的leet字符最多替换 code-10 个
21-29 从右至左, 将第一个遇到的leet字符最多替换 code-20 个
代码作用表
| 代码 | 原字符串 | 被替换后的新字符串 |
|---|---|---|
| 0 | as a airs trees | 45 4 41r5 tr335 |
| 1 | as a airs trees | 4s 4 4irs trees |
| 2 | as a airs trees | a5 a air5 tree5 |
| 11 | as a airs trees | 4s a airs trees |
| 12 | as a airs trees | 4s 4 airs trees |
| 13 | as a airs trees | 4s 4 4irs trees |
| 14 | as a airs trees | 4s 4 4irs trees |
| … | as a airs trees | 4s 4 4irs trees |
| 21 | as a airs trees | as a airs tree5 |
| 22 | as a airs trees | as a air5 tree5 |
| 23 | as a airs trees | a5 a air5 tree5 |
| 24 | as a airs trees | a5 a air5 tree5 |
| … | as a airs trees | a5 a air5 tree5 |
终点即起点,到你一展身手的时候了。
用法:
pydictor.py [options]
-base type
-char customchar
-chunk <chunk1> <chunk2> ...
-plug <pid6, pid8, extend>
-o output path
--sex <m, f, all>
--len minlen maxlen
--head prefix
--tail suffix
--encode <b64,md5,md516,sha1,url,sha256,sha512>
--conf conf file
--sedb
--shred prefix or file or directory
*[+] A Useful Hacker Dictionary Builder. [+]*
[+] Build by LandGrey email:[email protected]
optional arguments:
-h, --help show this help message and exit
-base Type
Choose from [d L c dL dc Lc dLc]
d digital [0 - 9]
L lowercase letters [a - z]
c capital letters [A - Z]
dL Mix d and L [0-9 a-z]
dc Mix d and c [0-9 A-Z]
Lc Mix L and c [a-z A-Z]
dLc Mix d, L and c [0-9 a-z A-Z]
-char Character Use [Custom Character] build the dictionary
-chunk Chunk [Chunk ...]
Use the string [Chunk Multiplication] build the dictionary
-plug Plug [Plug ...]
Choose plug from [pid6 pid8 extend]
pid6 [Id Card post 6 number] default sex:all
pid8 [Id Card post 8 number] default sex:all
extend [file path]
-o Output
Set the directory output path
default: pydictor\results
--sex Sex
Choose sex from [m f all]
m: Male f: Female all: Male and Female
Provided for [pid6 | pid8]
--len Minlen Maxlen
Minimun Length Maximun Length (excluded head | tail | encode)
Default: min=2 max=4
--head Prefix Add string head for the dictionary
--tail Suffix Add string tail for the dictionary
--encode Encode
Choose encode or encrytion from:
b64 base64 encode
md5 md5 encryption (32)
md516 md5 encryption (16)
sha1 sha1 encryption
url urlencode
sha256 sha256 encrytion
sha512 sha512 encrytion
--conf [Conf file]
Use the configuration file build the dictionary
Default: pydictor\build.conf
--sedb Enter the Social Engineering Dictionary Builder
--shred [target]
Safe shredded the [target]:
[!!! Warning !!!]
Once this function is enabled, the data will be shredded
default pydictor\results
common file specified the complete file path
prefix file <prefix> choice from 6 types as follow:
[base | chunk | conf | sedb | idcard | extend]
directory specified the complete directory
功能:
总览:
1. 在本程序的参数命令中,以"-"开头的命令,如"-base",其后至少要有1个参数;
2. 在本程序的参数命令中,以"--"开头的命令,如"--conf",其后若无参数,将使用程序默认数值,否则使用用户指定的一个参数;
3. 用户可以控制的程序的所有默认设置,如最大长度限制,字典的最大行数等,都在lib\data.py中;
如果受到限制,请先明确它们的意义后更改,否则不要轻易修改,以避免使程序异常;
1. 支持使用纯数字、纯小写字母或纯大写字母的任意位数爆破字典生成
例:
生成6位纯数字字典
python pydictor.py -base d --len 6 62. 支持使用数字、小写字母与大写字母两两组合的任意位数爆破字典生成
例:
生成数字和小写字母组成的所有2-4位长度字典
python pydictor.py -base dL --len 2 4 3. 支持使用数字、小写字母与大写字母3者组合的任意位数爆破字典生成
例:
生成数字、小写字母和大写字母组成的所有4-6位字典
python pydictor.py -base dLc --len 4 6 4. 支持使用自定义字符(包括特殊字符)的任意位数爆破字典生成
例:
生成由’aAbBcC123.’ 10个字符组成的所有6位到8位字典
python pydictor.py -char aAbBcC123. --len 6 8注: 当需要空格等特殊字符时,请加双引号包围所有自定义字符,如:”abcAB C123.”
5. 支持使用自定义字符串、字符生成所有排列可能性组合的字典
例:
生成由’abc’、’ABC’、’123’ 和’.’4个块组成的所有排列的可能性组合字典
python pydictor.py -chunk abc ABC 123 .注: 当需要空格等特殊字符时,请加双引号单独包围特殊字符,如:abc ” ” 123 asdf;此类字典的生成长度为块数的阶乘.
6. 支持使用特殊功能的字典生成插件
6.1 pid6插件
中国公民身份证后6位爆破字典生成
例:
生成中国男性公民的身份证后6位所有可能性组合字典
python pydictor.py -plug pid6 --sex m6.2 pid8插件
中国公民身份证后8位爆破字典生成
例:
生成所有中国公民的身份证后8位所有可能性组合字典
python pydictor -plug pid8 注: 不支持指定生成此类字典的长度,默认的–sex参数为全体(“all”)公民
6.3 extend插件
将收集到的目标元词组按内置规则扩展成爆破字典
例:
将’D:\1.txt’文件中的每一行进行扩展生成扩展字典
python pydictor -plug extend D:\1.txt 7. 支持指定生成的字典前缀(头)与后缀(尾)
例:
python pydictor.py -base L --len 1 4 --head a --tail 123注: 指定的头和尾并不包括在指定的长度(–len参数)中,而是在原来的长度基础上额外增加的。
8. 支持将生成的字典进行编码或加密
例:
python pydictor.py -base d --encode b64注: 支持 base64 urlencode编码, md5(32位) md516(16位) sha1 sha256 sha512加密
9. 支持指定输出目录
例:
python pydictor.py -base d --len 4 4 -o D:\output注: 如指定的目录不存在, 则会尝试创建;如果创建失败,则使用或创建默认的results目录;
10. 配置文件解析功能
此功能可以完成”-base”和”-char”的所有功能,并在此基础上有更精细化的提升;
python pydictor.py --conf 使用默认位置的build.conf 配置文件建立字典
python pydictor.py --conf D:\conf\my.conf 使用指定位置的配置文件建立字典
注: 具体解析规则如下,另可参考build.conf文件示例;
配置文件解析规则:
1. 解析的基本单位称为一个解析元,一个解析元包括五个解析元素,分别是:头、字符集、长度范围、编码方式、尾,其中的头与尾均可省略不写;
一个标准解析元的写法:head[characters]{minlength:maxlength}<encode-type>tail,一个示例解析元,如:a[0-9]{4:6}<none>_
其意义为生成以"a"为开头,以0到9共10个字符为字符集的,字符集生成长度为4到6位,不做任何编码的,并以"_"结尾的字典集合;
2. 暂时只支持一行解析,生成一个字典,一个生成好的字典中的一行为一条解析的一种可能;
3. 每一行当作一条解析,一条解析可包含一至十个解析元,以提供粒度更小的字典生成方式;
如:[4-6,a-c,A,C,admin]{3:3}<none>_[a,s,d,f]{2:2}<none>[789,!@#]{1:2}<none>,就包含了三个解析元;
值得注意的是字符集:
既可以按照字符的大小顺序,以"-"来连接,表示用多个单个字符做为元素组成的字符集;
又可以用","来分隔多个字符集,或单个字符,或单个字符串,来作为字符集中的一个元素;
支持的编码方式:
none 不进行任何编码
b64 base64 编码
md5 md5 摘要输出32位
md516 md5 摘要输出16位
sha1 sha1 摘要
url urlencode
sha256 sha256 摘要算法
sha512 sha512 摘要算法
4. 从控制范围上看解析元素,长度范围的控制范围仅为字符集中的生成长度,不包括头、尾以及编码后的长度,而编码方式的控制范围为一个解析元;
5. 配置文件的一行中的第一个字符为"#"字符的,代表注释,程序将不再解析本行;
6. 用配置文件方式可产生精确至一位的高度可控字典,推荐有需求的人员使用;
另附字符的大小顺序(从小到大,处在[]中间的):
[ !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~]
11. 安全删除指定文件或目录功能
python pydictor.py --shred 删除默认的 results 目录及其所有字典文件
python pydictor.py --shred base 删除当前输出目录(默认为results)下,以"BASE"开头的所有字典文件
因为输出时字典文件名前缀固定,所以可以用这种方式删除某一类字典文件
当前支持的前缀(不区分大小写)有6种:base、chunk、conf、sedb、idcard、extend
另外,–shred选项还支持将传入的任意位置的一个目录、文件,整个的安全删除,程序会自动判断待删除的是目录还是文件,从而自动工作
python pydictor.py --shred /data/mess 删除整个/data/mess目录
python pydictor.py --shred D:\mess\1.zip 删除D:\mess\1.zip 文件
为提高安全删除速度,默认使用1遍擦除重写,如有更高安全需要,可修改lib\data.py中的file_rewrite_count和dir_rewrite_count,提高擦除次数;建议最高修改次数为3次;
注: 安全删除功能请谨慎使用,造成重要数据不可恢复与本程序开发者无任何关系!
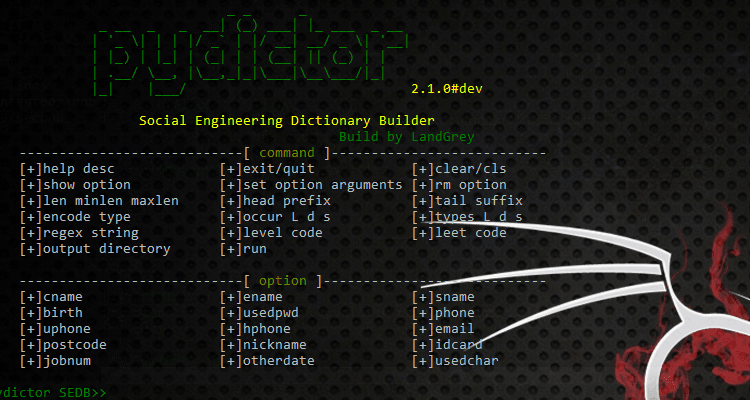
12. 支持建立社会工程学字典
例:
进入社工字典生成界面
python pydictor.py --sedb _______ __ _ _
|_ __ \ | ] (_) / |_
| |__) |_ __ .--.| | __ .---.`| |-' .--. _ .--.
| ___/[ \ [ ]/ /'`' | [ | / /'`\]| | / .'`\ \[ `/'`\]
_| |_ \ '/ / | \__/ | | | | \__. | |,| \__. | | |
|_____| [\_: / '.__.;__][___]'.___.'\__/ '.__.' [___]
\__.'
Social Engineering Dictionary Builder
Build by LandGrey
----------------------------------[ command ]------------------------------------
[+]help desc (View the description) | [+]show setting (Show current settings)
[+]cls/clear (Clean the screen) | [+]quit/exit (Quit the progress)
[+]run (Build the dictionary) |
|
Usage Exp :show (Show all of settings) | help [setting] (Show selected setting)
-------------------------------[ setting options ]--------------------------------
[+]cname [+]ename [+]sname | [+]birth [+]usedpwd [+]phone
[+]uphone [+]hphone [+]email | [+]postcode [+]nickname [+]idcard
[+]jobnum [+]otherdate [+]usedchar |
|
Usage Exp :sname zhang wei zw zwell | * Each setting supports multiple values
pydictor SEDB>>
–
社会工程学字典生成功能介绍:
1. 内置15项收集数据
cname Chinese name's phonetic 中文名拼音全拼
ename English name 英文名
sname Simple spellings phonetic 姓名简拼
birth Birthday [YYYYMMDD] 生日
usedpwd Used password 曾用密码
phone Cell phone number 手机号
uphone Used phone 曾用手机号
hphone Homephone number 家庭座机号
email E-mail accounts 电子邮箱账号
postcode Postcode 家庭邮政编码
nickname Commonly used nickname 常用昵称
idcard Identity card number 身份证号
jobnum Job or student number 学号或工号或其简写等
otherdate Others date [YYYYMMDD] 其他亲人生日等特殊日期
usedchar Commonly used characters 其他社交平台账号等常用字符
2. 命令速通
进入 Social Engineering Dictionary Builder 界面后,可以使用
[项目名] [v1] [...] 设置某项数据的值
help desc 查看15项数据的意义描述;
help [具体项] 查看某项数据的意义描述;
show 查看15项数据的当前设置情况;
show [具体项] 查看某项数据的当前设置情况;
run 建立字典
cls 清除命令行文字
clear 清除命令行文字
quit 退出
exit 退出
3. 15项数据说明
(1) 以上15项,每一项都支持用空格隔开输入多个数据,不清楚的可以不填;
命令: sname zhang wei zw zwell
(2) 其他的一些目标信息可以在otherid和usedchar项目输入;
比如宠物名、个人图腾、特殊意义字符、爱人亲人生日等等各种相关的信息
(3) 准确的社工字典不仅需要大量的目标信息,而且还需要结合目标的性格特征,比如:懒惰、完美主义、身份特征、目标平台等;
然而,由于缺少人物画像,对目标的性格和爆破平台密码策略不详,所以生成字典难免可能有累赘,不准确,请谅解。
(4) 为了解决(3)的问题,可以自己在rules目录中修改/增加规则,修改相应代码来定制相关的生成策略。
development:
开发理念:
实用、高效、中小型字典、即用即得
程序特点:
小巧、灵活、实用、兼容python2|3、支持Windows与Linux平台
目录结构:
│
│ build.conf
│ pydictor.py
│
├─build-in dict
│ MariaBotPass.txt
│ OrdinaryUserCommonPass.txt
│ TinyCommonWifiWeakPass.txt
│
├─core
│ │ BASE.py
│ │ CHUNK.py
│ │ CONF.py
│ │ SEDB.py
│ └─__init__.py
│
│
├─lib
│ │ command.py
│ │ confparse.py
│ │ data.py
│ │ encode.py
│ │ fun.py
│ │ shreder.py
│ │ text.py
│ └─__init__.py
│
│
├─plugins
│ │ extend.py
│ │ idcard.py
│ └─ __init__.py
│
│
├─results
└─rules
│ CBrule.py
│ EBrule.py
│ SBrule.py
│ SingleRule.py
│ WeakPass.py
└─ __init__.py
解释:
build.conf 生成字典默认使用的配置文件,使用时需要根据自己的需求修改;
pydictor.py 程序入口文件;
build-in dict 内置高效实用的字典文件;
core 程序主功能文件存放的目录;
lib 提供一些数据和简单功能;
plugins 插件目录;
results 生成字典的默认保存目录;
rules 存放社会工程学字典的生成规则;用法示例:
old document for English usage reference
核心功能字典
1. 基础字典
python pydictor.py -base L --len 2 3 --encode b64
python pydictor.py -base dLc --len 1 3 -o /awesome/pwd
python pydictor.py -base d --len 4 4 --head Pa5sw0rd --output D:\exists\or\not\dict.txt
2. 自定义字符集字典
python pydictor.py -char "asdf123._@ " --len 1 3 --tail @site.com3. 排列组合字典
python pydictor.py -chunk abc 123 "!@#" @ . _ " " --head a --tail @pass --encode md54. 语法引擎解析字典
python pydictor.py --conf 用默认的"/funcfg/build.conf"文件建立字典
python pydictor.py --conf /my/other/awesome.conf
python pydictor.py --conf "[0-9]{6,6}<none>[a-f,abc,123,!@#]{1,1}<none>" --encode md5 --output parsing.txt
5. 规则扩展字典
python pydictor.py -extend bob --level 4 --len 4 12
python pydictor.py -extend liwei zwell.com --leet 0 1 2 11 21 --level 2 --len 6 16 --occur "<=10" ">0" "<=2" -o /possbile/wordlist.lst
6. 社会工程学字典
python pydictor.py --sedb _ _ _
_ __ _ _ __| (_) ___| |_ ___ _ __
| '_ \| | | |/ _` | |/ __| __/ _ \| '__|
| |_) | |_| | (_| | | (__| || (_) | |
| .__/ \__, |\__,_|_|\___|\__\___/|_|
|_| |___/
Social Engineering Dictionary Builder
Build by LandGrey
----------------------------[ command ]----------------------------
[+]help desc [+]exit/quit [+]clear/cls
[+]show option [+]set option arguments [+]rm option
[+]len minlen maxlen [+]head prefix [+]tail suffix
[+]encode type [+]occur L d s [+]types L d s
[+]regex string [+]level code [+]leet code
[+]output directory [+]run
----------------------------[ option ]----------------------------
[+]cname [+]ename [+]sname
[+]birth [+]usedpwd [+]phone
[+]uphone [+]hphone [+]email
[+]postcode [+]nickname [+]idcard
[+]jobnum [+]otherdate [+]usedchar
pydictor SEDB>>
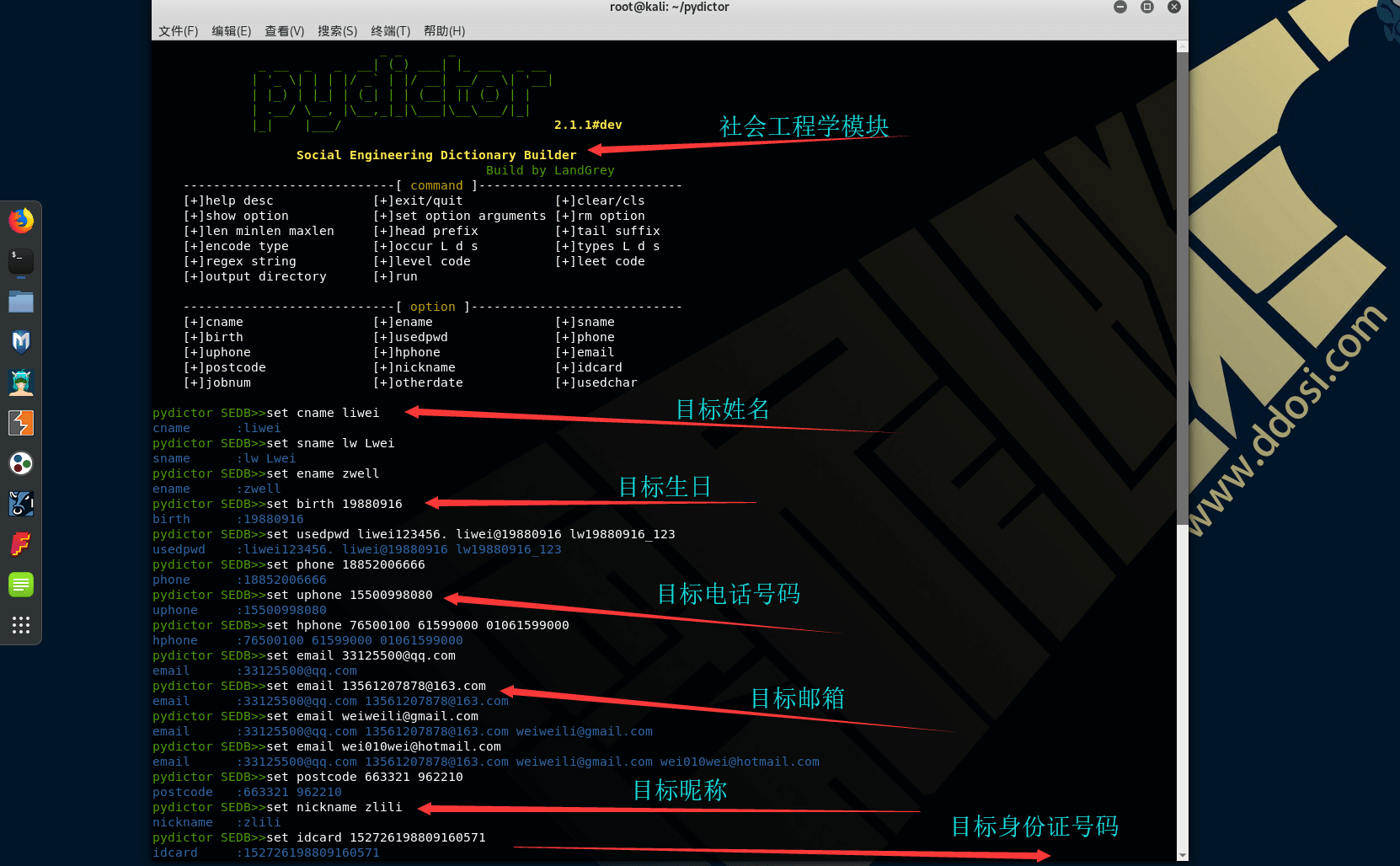
根据以下信息:
| information items | value |
|---|---|
| chinese name | 李伟 |
| pinyin name | liwei |
| simple name | lw |
| simple name | Lwei |
| english name | zwell |
| birthday | 19880916 |
| used password | liwei123456. |
| used password | liwei@19880916 |
| used password | lw19880916_123 |
| used password | abc123456 |
| phone number | 18852006666 |
| used phone number | 15500998080 |
| home phone | 76500100 |
| company phone | 010-61599000 |
| email account | [email protected] |
| email account | [email protected] |
| email account | [email protected] |
| email account | [email protected] |
| home postcode | 663321 |
| now place postcode | 962210 |
| common nickname | zlili |
| id card number | 152726198809160571 |
| student id | 20051230 |
| job number | 100563 |
| father birthday | 152726195910042816 |
| mother birthday | 15222419621012476X |
| boy/girl friend brithday | 152726198709063846 |
| friend brithday | 152726198802083166 |
| pet name | tiger |
| crazy something | games of thrones |
| special meaning numbers | 176003 |
| special meaning chars | m0n5ter |
| special meaning chars | ppdog |
使用命令
python pydictor.py --sedb
set cname liwei
set sname lw Lwei
set ename zwell
set birth 19880916
set usedpwd liwei123456. liwei@19880916 lw19880916_123
set phone 18852006666
set uphone 15500998080
set hphone 76500100 61599000 01061599000
set email [email protected]
set email [email protected]
set email [email protected]
set email [email protected]
set postcode 663321 962210
set nickname zlili
set idcard 152726198809160571
set jobnum 20051230 100563
set otherdate 19591004 19621012
set otherdate 19870906 19880208
set usedchar tiger gof gamesthrones 176003 m0n5ter ppdog查看当前配置然后生成字典
show
run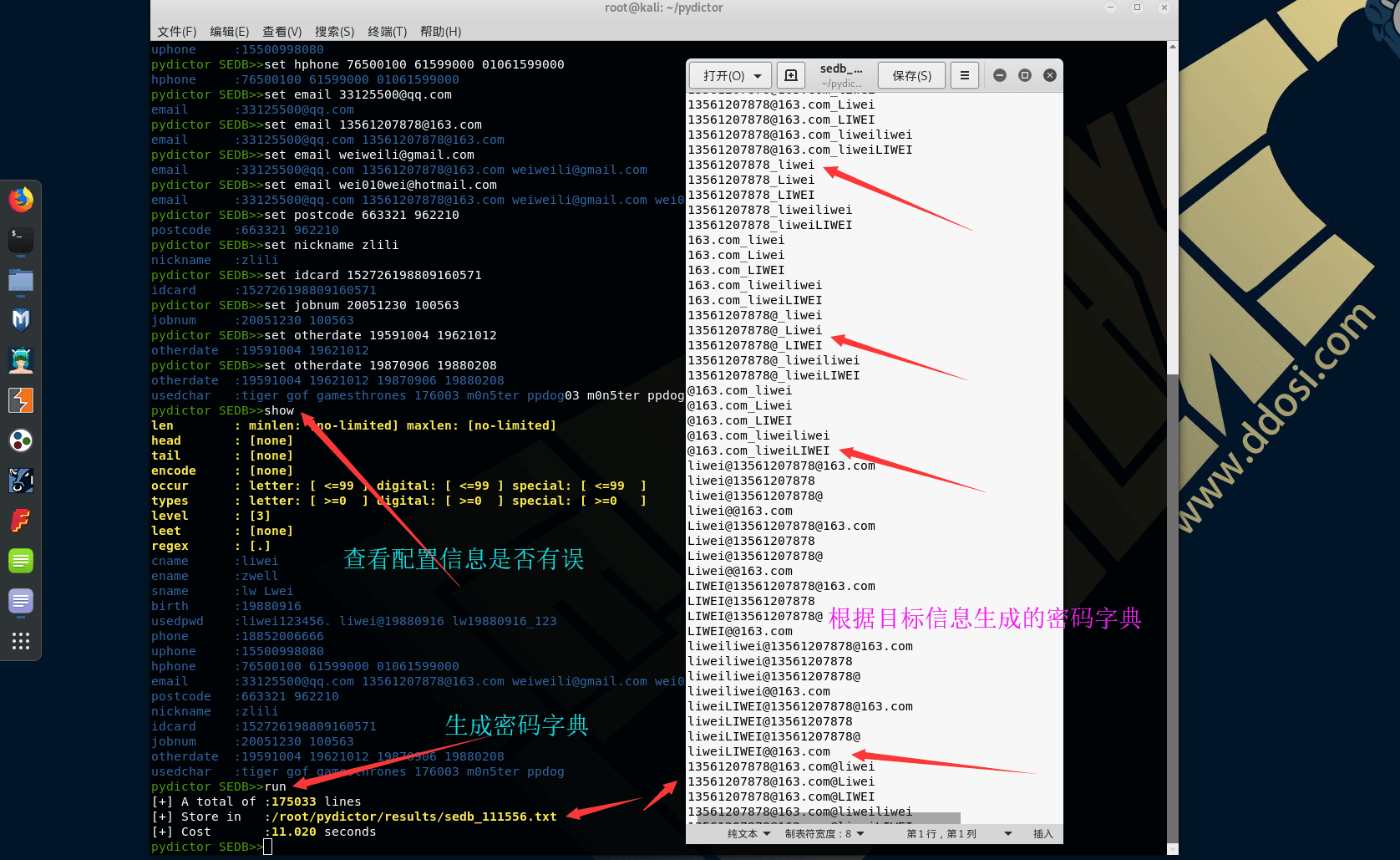
插件型字典(可自己根据API文档开发)
1. 一段时间内的生日字典
python pydictor.py -plug birthday 19800101 20001231 --len 6 82. 身份证后4/6/8位字典
python pydictor.py -plug pid4
python pydictor.py -plug pid6 --encode b64
python pydictor.py -plug pid8 --encode sha1 -o pid8.txt
3. 网页原始关键词字典
python pydictor.py -plug scratch 用/funcfg/scratch.sites 文件中的多行 url 作为输入
python pydictor.py -plug scratch http://www.example.com
内置工具(可自己根据API文档开发)
1. 字典合并工具
python pydictor.py -tool combiner /my/mess/dir2. 字典比较工具
python pydictor.py -tool comparer big.txt small.txt3. 词频统计工具
python pydictor.py -tool counter s huge.txt 1000
python pydictor.py -tool counter v /tmp/mess.txt 100
python pydictor.py -tool counter vs huge.txt 100 --encode url -o fre.txt
4. 字典处理工具
python pydictor.py -tool handler raw.txt --tail @awesome.com --encode md5
python pydictor.py -tool handler raw.txt --len 6 16 --occur "" "=6" "<0" --encode b64 -o ok.txt
5. 安全擦除字典工具
python pydictor.py -tool shredder 擦除当前输出目录下所有字典文件
python pydictor.py -tool shredder base 擦除当前输出目录下所有以"base"开头的字典文件
python pydictor.py -tool shredder /data/mess
python pydictor.py -tool shredder D:\mess\1.zip
6. 合并去重工具
python pydictor.py -tool uniqbiner /my/all/dict/
7. 字典去重工具
python pydictor.py -tool uniqifer /tmp/dicts.txt --output /tmp/uniq.txt
8. 多字典文件组合工具
python pydictor.py -tool hybrider heads.txt some_others.txt tails.txt