
目录导航
# !/usr/local/bin/python3
# -*- coding:utf-8 -*-
__author__ = 'jerry'
from collections import defaultdict
import sys
import json
from lib.common.basic import getExtension, getDomain
from lib.third.nyawc.Crawler import Crawler
from lib.third.nyawc.CrawlerActions import CrawlerActions
from lib.third.nyawc.Options import Options
from lib.third.nyawc.http.Request import Request
from lib.utils.extension import IGNORED_EXTESIONS, EXCEL_EXTENSIONS, WORD_EXTENSIONS, PDF_EXTENSIONS
import config
class LinksCrawler():测试效果如下:
使用步骤:
安装:
# 下载 git clone https://github.com/jerrychan807/WSPIH.git # 进入项目目录 cd WSPIH # 安装依赖模块 pip3 install -r requirements.txt # 修改配置文件(若不修改,则使用默认配置) vi config.py
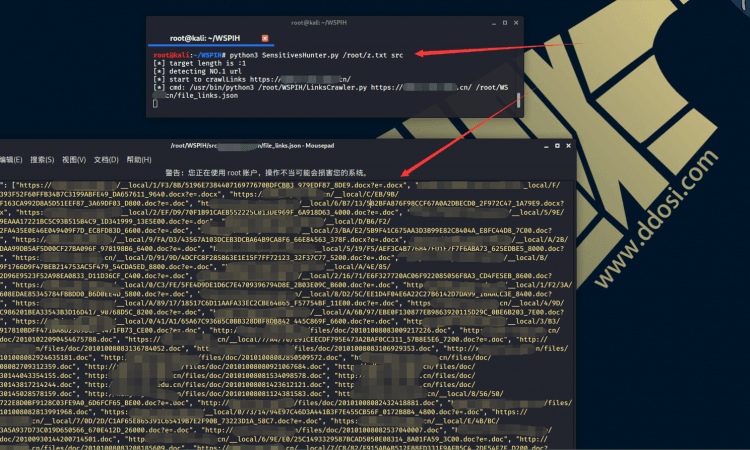
开始扫描:
# 使用 python3 SensitivesHunter.py 目标文件 结果文件夹 # 示例 python3 SensitivesHunter.py targets/http-src-1-100.txt src
查看结果:
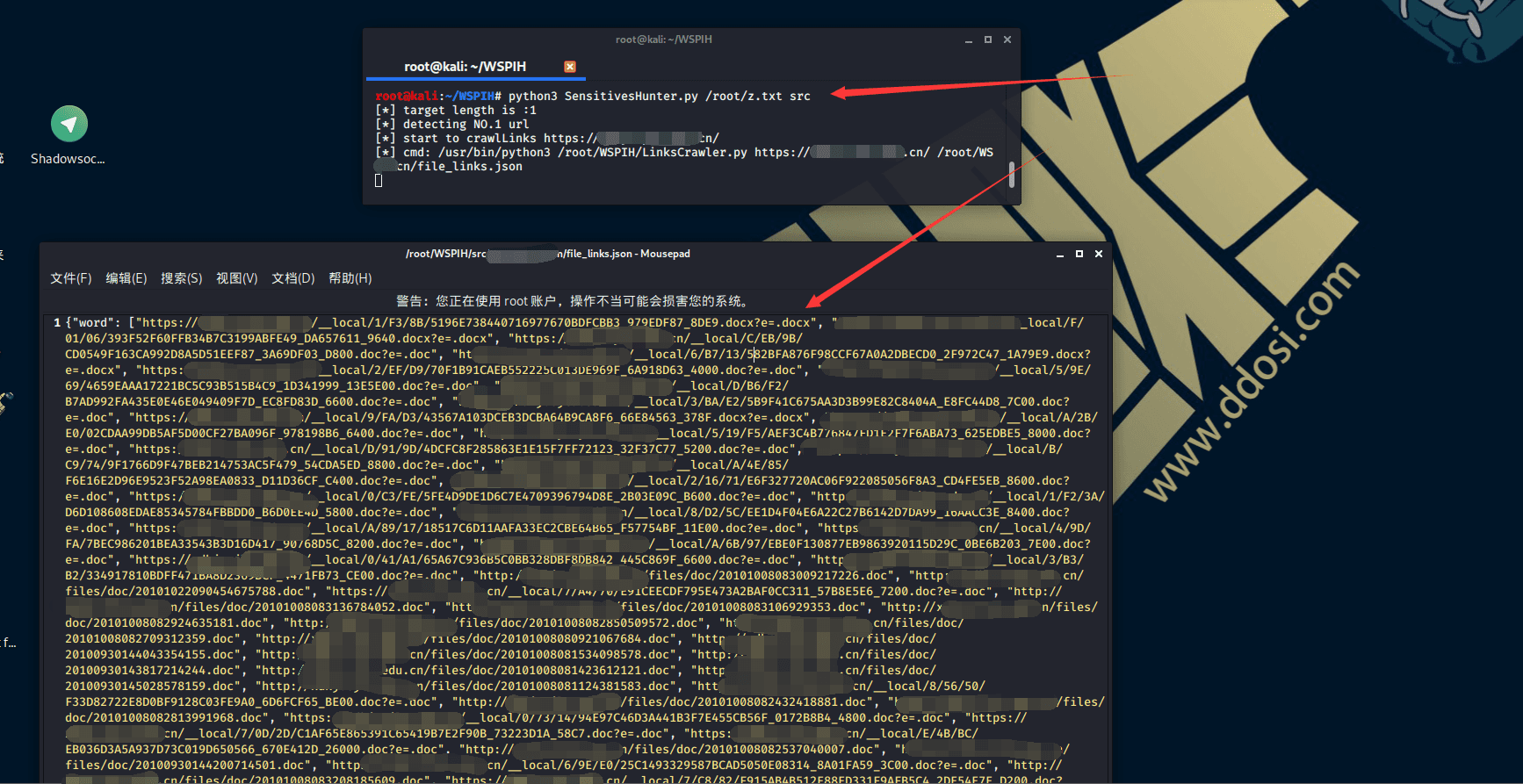
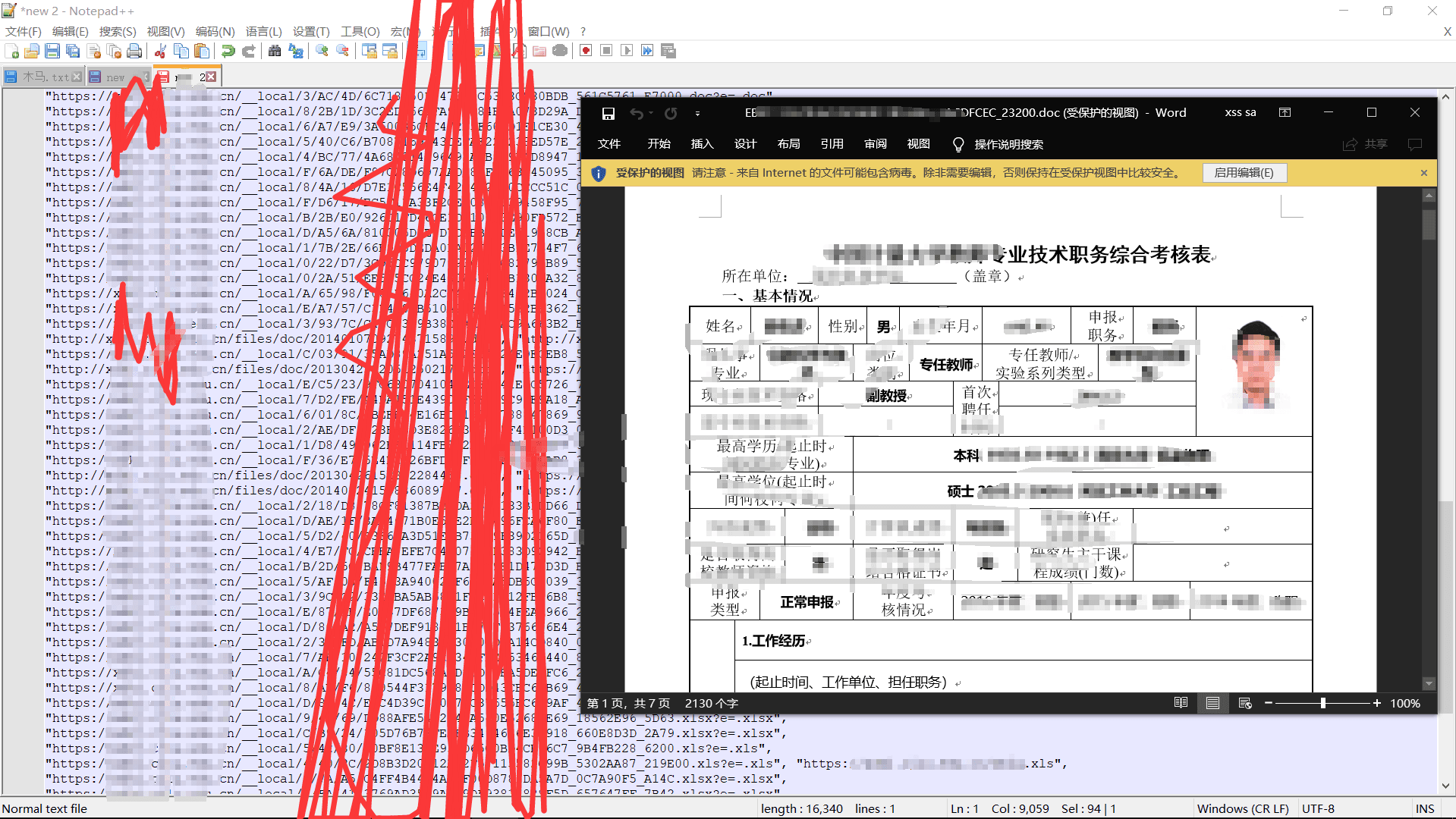
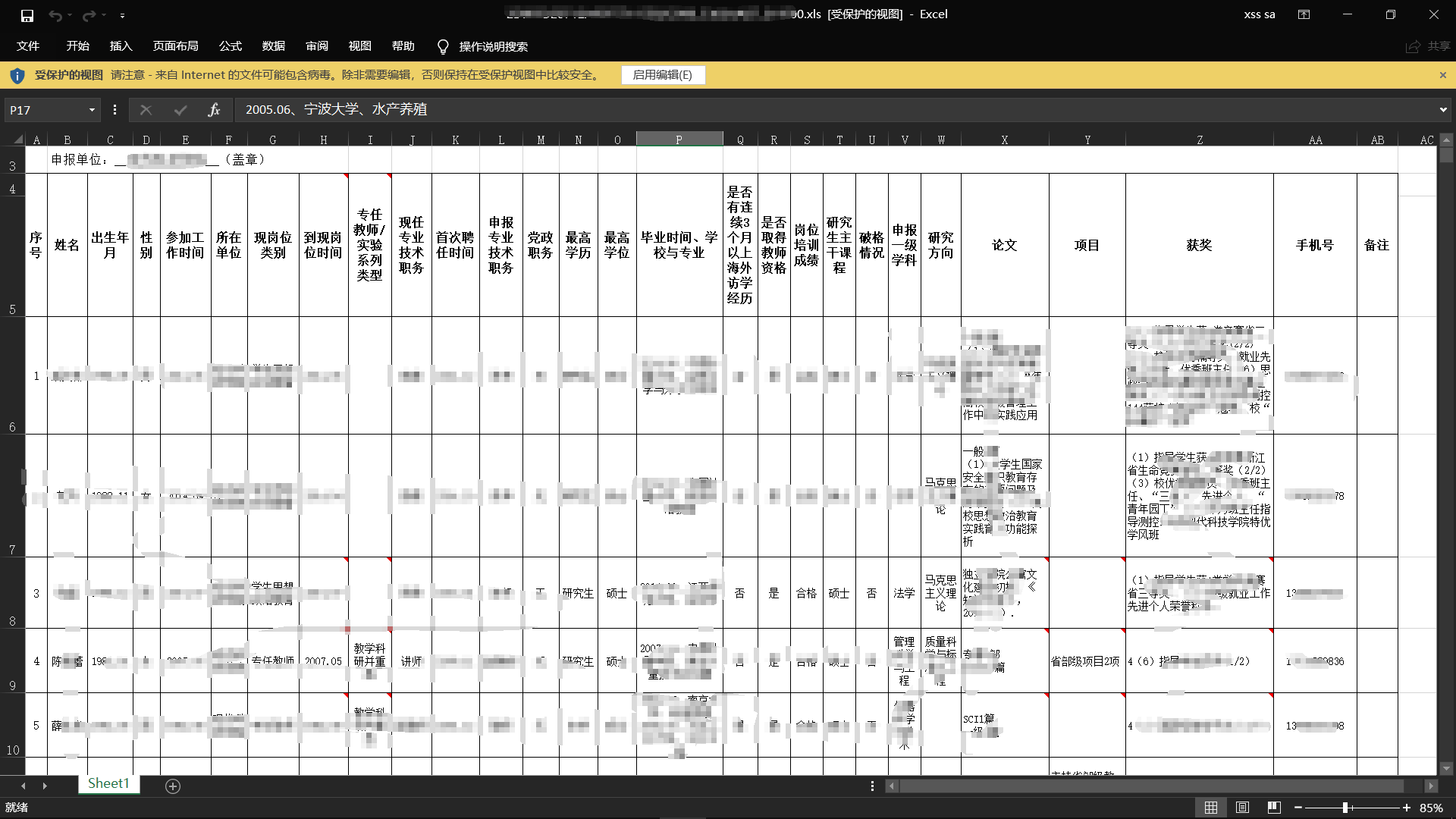
如果有扫出敏感文件…
单个结果:
- 每个目标的结果会保存在 结果文件夹/对应域名 下.
- 会保留有问题的敏感文件
- 文件链接
file_links.json、敏感结果result.json
汇总结果:
# 输出最终汇总的结果 python3 CombineResult.py 结果文件夹 # 示例 python3 CombineResult.py src
- 查看最终合并的结果:
all_result.txt