
目录导航
URLBrute介绍
URLBrute是一个扫描网站二级域名,爆破网站目录结构的工具,可以在python3和python2下一起使用。
项目地址
GitHub : https://github.com/ReddyyZ/URLBrute
依赖关系
urlbrute.py
- requests >= 2.21.0
- bs4 >= 0.0.1
- datetime >= 4.3
URLBrute下载地址:
① GitHub
② w.ddosi.workers.dev Google网盘
URLBrute安装方法
①在linux系统中安装
chmod +x install.sh
sudo ./install.sh②在windows中安装
安装python 3.7,然后以管理员身份运行cmd:
install.batURLBrute使用演示
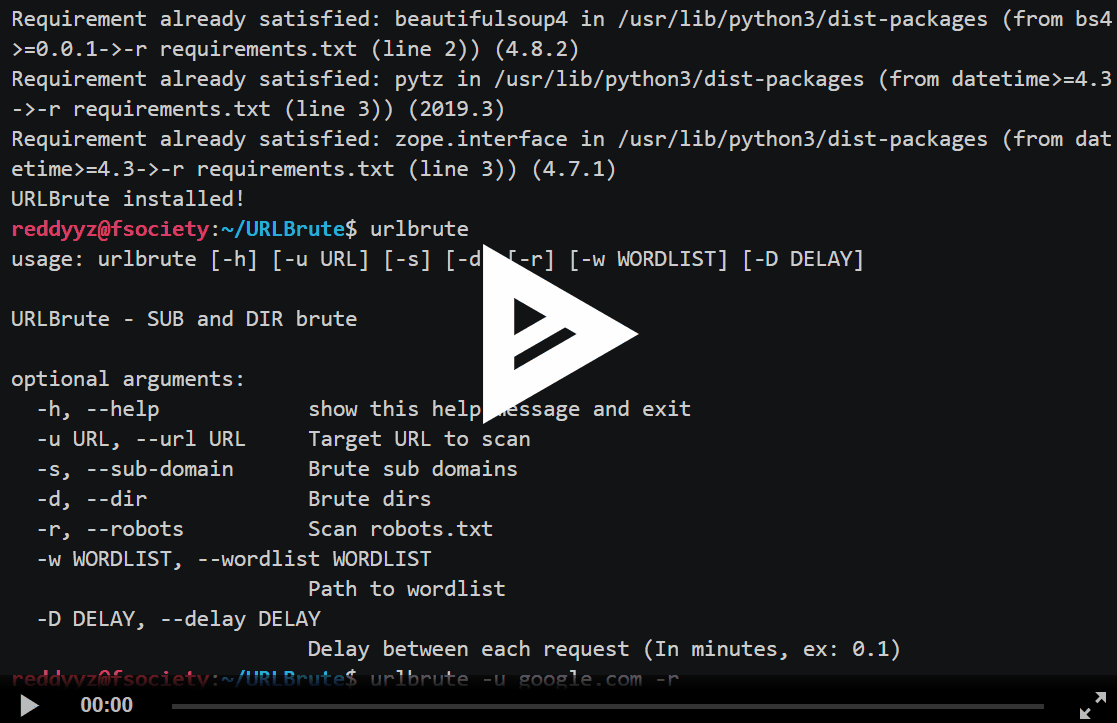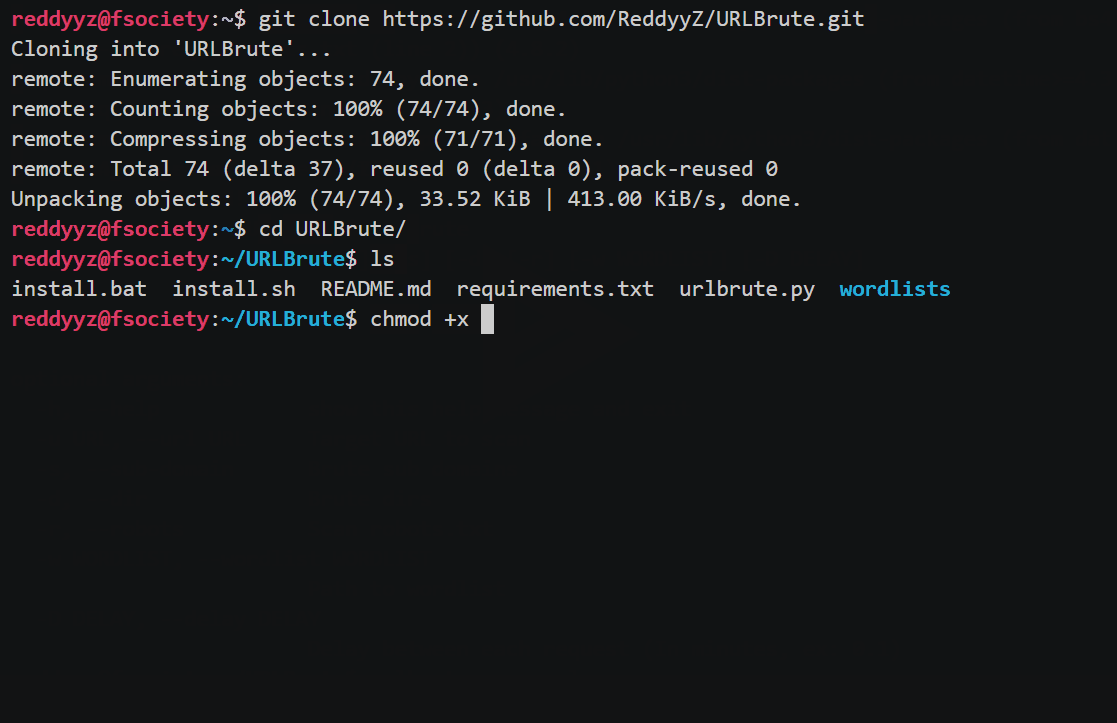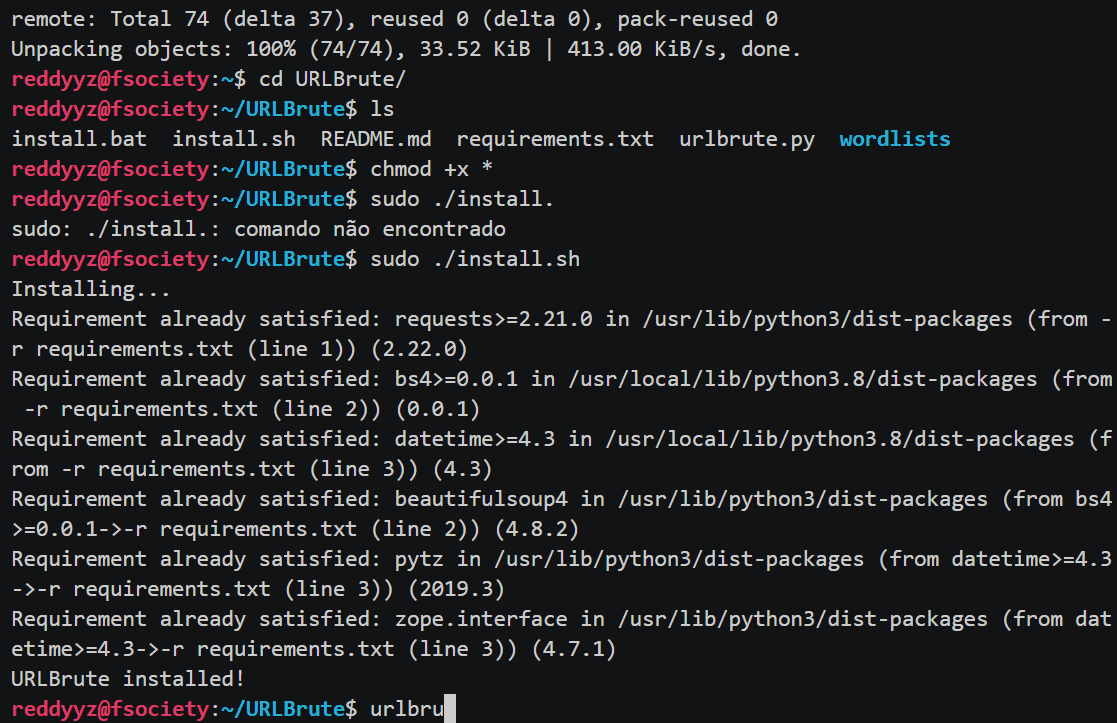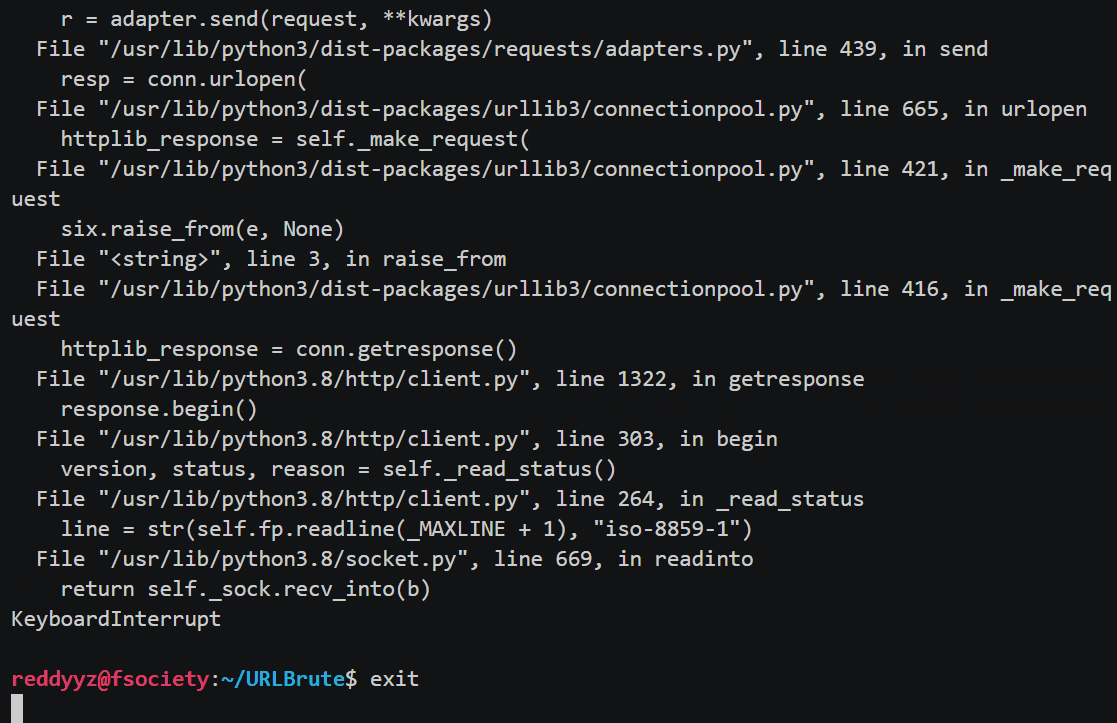
urlbrute.py
#!/usr/bin/env python3
import requests,argparse,os,sys,time,datetime
from os.path import isfile, join
from bs4 import BeautifulSoup
header = {
'User-Agent': 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)',
'Referer': 'http://www.google.com'
}
timeout = 0
mode = "NONE"
if os.name == 'nt':
clear = lambda:os.system('cls')
urlbrute_path = "C:\\URLBrute"
else:
clear = lambda:os.system('clear')
urlbrute_path = "/usr/share/URLBrute"
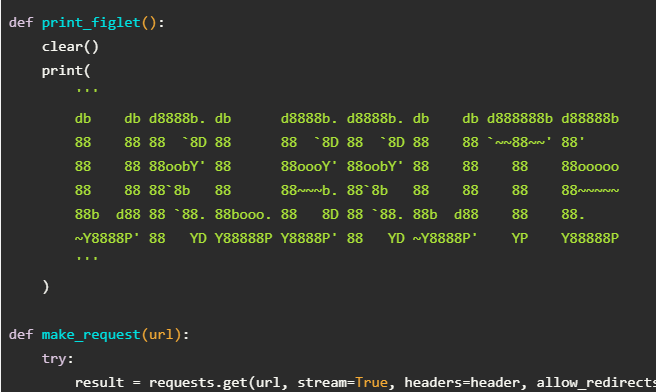
def print_figlet():
clear()
print(
'''
db db d8888b. db d8888b. d8888b. db db d888888b d88888b
88 88 88 `8D 88 88 `8D 88 `8D 88 88 `~~88~~' 88'
88 88 88oobY' 88 88oooY' 88oobY' 88 88 88 88ooooo
88 88 88`8b 88 88~~~b. 88`8b 88 88 88 88~~~~~
88b d88 88 `88. 88booo. 88 8D 88 `88. 88b d88 88 88.
~Y8888P' 88 YD Y88888P Y8888P' 88 YD ~Y8888P' YP Y88888P
'''
)
def make_request(url):
try:
result = requests.get(url, stream=True, headers=header, allow_redirects=True, timeout=22)
return result
except Exception as e:
print(e)
return False
def __list__(to_list="wordlists",path=None):
print_figlet()
if to_list == "wordlists":
wordlists_path = join(urlbrute_path,"wordlists")
if path:
wordlists_path = join(wordlists_path,path)
files = []
dirs = []
for file in os.listdir(wordlists_path):
if isfile(join(wordlists_path,file)):
files.append(file)
else:
dirs.append(file)
for _dir in dirs:
print("{} - DIR".format(_dir))
for _file in files:
file_size = os.stat(join(wordlists_path,_file)).st_size / (1024*1024)
print("{} - FILE : {} MB".format(_file,str(file_size).split('.')[0]))
def read_wordlist(path):
words = []
if os.path.exists(path):
pass
else:
if os.path.exists("C:\\URLBrute\\wordlists\\%s" % path):
path = "C:\\URLBrute\\wordlists\\%s" % path
elif os.path.exists("/usr/share/URLBrute/wordlists/%s" % path):
path = "/usr/share/URLBrute/wordlists/%s" % path
else:
return False
with open(path,'r') as _file:
wordlist = _file.readlines()
for line in wordlist:
line = line.replace('\n','')
if line.startswith('#') or not line:
continue
words.append(line)
return words
def scan_robots(url):
robot_dirs = []
robots_url = url + '/robots.txt'
res = make_request(robots_url)
if res == False:
print('[-]Robots.txt not found!')
return False
if res.status_code != 200:
return False
soup = BeautifulSoup(res.text)
data = soup.get_text()
res.close()
print('[*]Scanning robots.txt')
print(data)
time.sleep(5)
for line in data.split('\n'):
if line.startswith("Disallow: "):
full_url = "{}{}".format(url,line.split(' ')[1])
response = make_request(url)
if response == False:
continue
print('[+]Testing {} - {}'.format(full_url, res.status_code))
if res.status_code != 200:
continue
robot_dirs.append(full_url)
if robot_dirs:
print("[+]Founded {} dirs".format(len(robot_dirs)))
for _dir in robot_dirs:
print('[+]{}'.format(_dir))
else:
print("[-]Not found any dir")
def subdomain_brute(url,wordlist):
global timeout
if url.startswith('https://'):
url = url.replace('https://','')
https = True
elif url.startswith('http://'):
url = url.replace('http://','')
https = False
_subs = wordlist
_exist_subs = []
print("[*]Starting SUBDOMAIN brute")
print_figlet()
for _sub in _subs:
if https:
url_to_scan = "https://{}.{}".format(_sub,url)
else:
url_to_scan = "http://{}.{}".format(_sub,url)
print(url_to_scan)
print(_sub)
response = make_request(url_to_scan)
if response == False:
print("[-]Error testing: {}".format(url_to_scan))
continue
print("[*]Testing: {} - {}".format(url_to_scan,response.status_code))
if response.status_code == 200:
_exist_subs.append(_sub)
if timeout:
time.sleep(timeout)
response.close()
print("[*]Scan complete!")
time.sleep(3)
if _exist_subs:
print_figlet()
print('[+]{} subs founded'.format(len(_exist_subs)))
now = datetime.datetime.now()
filename = 'logs/sub_domains/{}-{}-{} {}h-{}m.log'.format(now.strftime("%y"), now.strftime("%m"), now.strftime("%d"), now.strftime("%H"), now.strftime("%M"))
with open(filename, "w") as out_file:
out_file.write("[+]{} subs founded\n".format(len(_exist_subs)))
for sub in _exist_subs:
print("[+]http://{}.{}".format(sub,url))
out_file.write("[+]http://{}.{}\n".format(sub,url))
print("[*]Log saved on {}".format(filename))
else:
print("[-]Not found any sub")
return True
def dirs_brute(url,wordlist):
global timeout
_dirs = wordlist
_exist_dirs = []
print("[*]Starting DIR brute")
print_figlet()
for _dir in _dirs:
url_to_scan = url+'/'+_dir
result = make_request(url_to_scan)
if result == False:
print('[-]Error testing: {}'.format(url_to_scan))
continue
print('[*]Testing: {} - {}'.format(url_to_scan,result.status_code))
if result.status_code == 200:
_exist_dirs.append(_dir)
if timeout:
time.sleep(timeout)
result.close()
print('[*]Scan complete!')
time.sleep(3)
if _exist_dirs:
print_figlet()
print('[+]{} dirs founded\n'.format(len(_exist_dirs)))
now = datetime.datetime.now()
filename = 'logs/dirs/{}-{}-{} {}h-{}m.log'.format(now.strftime("%y"), now.strftime("%m"), now.strftime("%d"), now.strftime("%H"), now.strftime("%M"))
with open(filename, "w") as out_file:
out_file.write("[+]{} dirs founded\n\n".format(len(_exist_dirs)))
for _dir in _exist_dirs:
print("[+]{}/{}".format(url,_dir))
out_file.write("[+]{}/{}\n".format(url,_dir))
print("\n[*]Log saved on {}".format(filename))
else:
print('[-]Not found any dir')
return True
def set_arguments():
global timeout, mode
parser = argparse.ArgumentParser(description='URLBrute - SUB and DIR brute')
parser.add_argument('-u','--url',type=str,help='Target URL to scan')
parser.add_argument('-s','--sub-domain',action="count",default=0,help='Brute sub domains')
parser.add_argument('-d','--dir',action="count",default=0,help='Brute dirs')
parser.add_argument('-r','--robots',action="count",default=0,help='Scan robots.txt')
parser.add_argument('-w','--wordlist',type=str,help='Path to wordlist')
parser.add_argument('-l','--list',type=str,default=None,help='List specified thing. Ex: --list wordlists')
parser.add_argument('-S','--sub-dir',type=str,default=None,help='Sub Dir to be listed. Ex: --list wordlists --path test (sub-dir in wordlists)')
parser.add_argument('-D','--delay',type=int,help='Delay between each request (In minutes, ex: 0.1)')
args = parser.parse_args()
if args.list == "wordlists":
sys.exit(__list__(path=args.sub_dir,to_list="wordlists"))
if not args.url:
sys.exit(parser.print_help())
if not args.wordlist:
if not args.dir and not args.sub_domain and args.robots:
pass
else:
sys.exit(parser.print_help())
if args.delay:
timeout = args.delay
if args.sub_domain:
mode = "SUB"
elif args.dir:
mode = "DIR"
elif args.robots:
mode = "ROBOTS"
else:
sys.exit(parser.print_help())
return args
if __name__ == '__main__':
args = set_arguments()
if not args.url.startswith('http://') and not args.url.startswith('https://'):
url = 'http://{}'.format(args.url)
if mode == "SUB" or mode == "DIR":
wordlist = read_wordlist(args.wordlist)
if not wordlist:
sys.exit("[-]Wordlist dont exists!")
if mode == "SUB":
subdomain_brute(url,wordlist)
elif mode == "DIR":
dirs_brute(url,wordlist)
elif mode == "ROBOTS":
scan_robots(url)
else:
pass