
目录导航
引言
当今信息化时代下,存在于各类计算机设备中的数据信息已成为越来越多刑事案件侦查的线索来源。Windows操作系统作为当今全球计算机使用率最高的操作系统,针对Windows操作系统的电子数据取证一直是电子数据取证领域研究的重点之一例,其中针对Windows操作系统中用户常用应用软件的行为取证分析,成为公安以及黑客组织用来突破的途径之一。
中文输入法作为Windows中文操作系统必备的一款应用程序,不仅支持中文文字编码和输入的功能,还具有自定义、自学习用户词库功能,这一功能将系统用户常用或者符合用户用语习惯的字词句以一种特定的结构形式存储成独立的词库数据集文件,以方便后期提高输入效率。这类用户词库文件留存了大量的与系统用户直接相关的输入痕迹信息,如目标姓名、地址、谈话内容等关键词,都能在输入法用户词库中有所体现,但用户词库中所存储的这些信息往往被取证人员忽略。
输入法词库位置
通过对Win10系统自带中文输入法程序运行进程的分析,发现与中文输入法相关的用户词库文件主要存储在
%USERPROFILE%\AppData\Roaming\Microsoft\InputMethod\Chs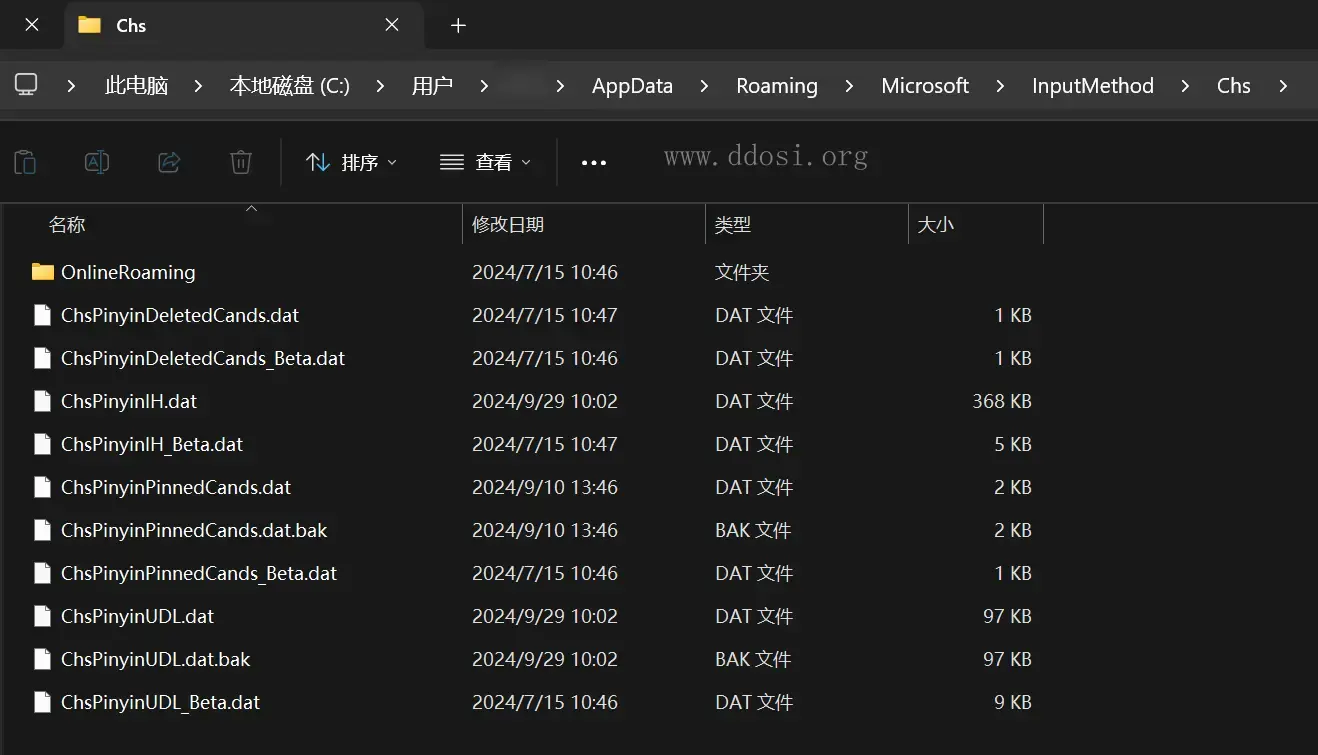
对所有文件的属性信息分析,发现其中文件名分别为ChsPinyinIH.dat和ChsPinyinUDL.dat的两个DAT文件,其属性信息会随着系统用户输入行为的发生而不断变化。但由于其是DAT类型文件,无法直接用常规方法获取记录信息。
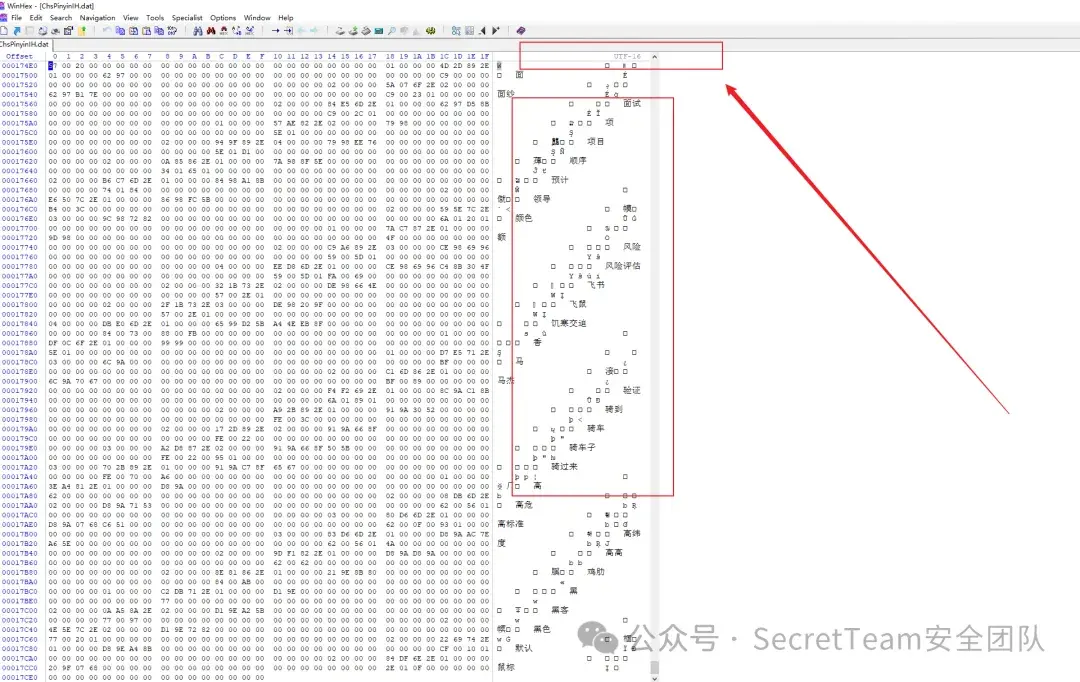
因此,利用010editor对这两个文件进行分析,如图1所示,发现存储的信息具有一定规律性,数据块之间存在明显分隔,并且在Unicode方式显示下,可以很明显发现文件名分别为ChsPinyinlH和ChsPinyinUDL的DAT文件中零散存储着系统用户之前输入的字词句信息,并且均以Unicode明码的方式保存在数据区中。
ChsPinyinIH.dat
ChsPinyinUDL.dat
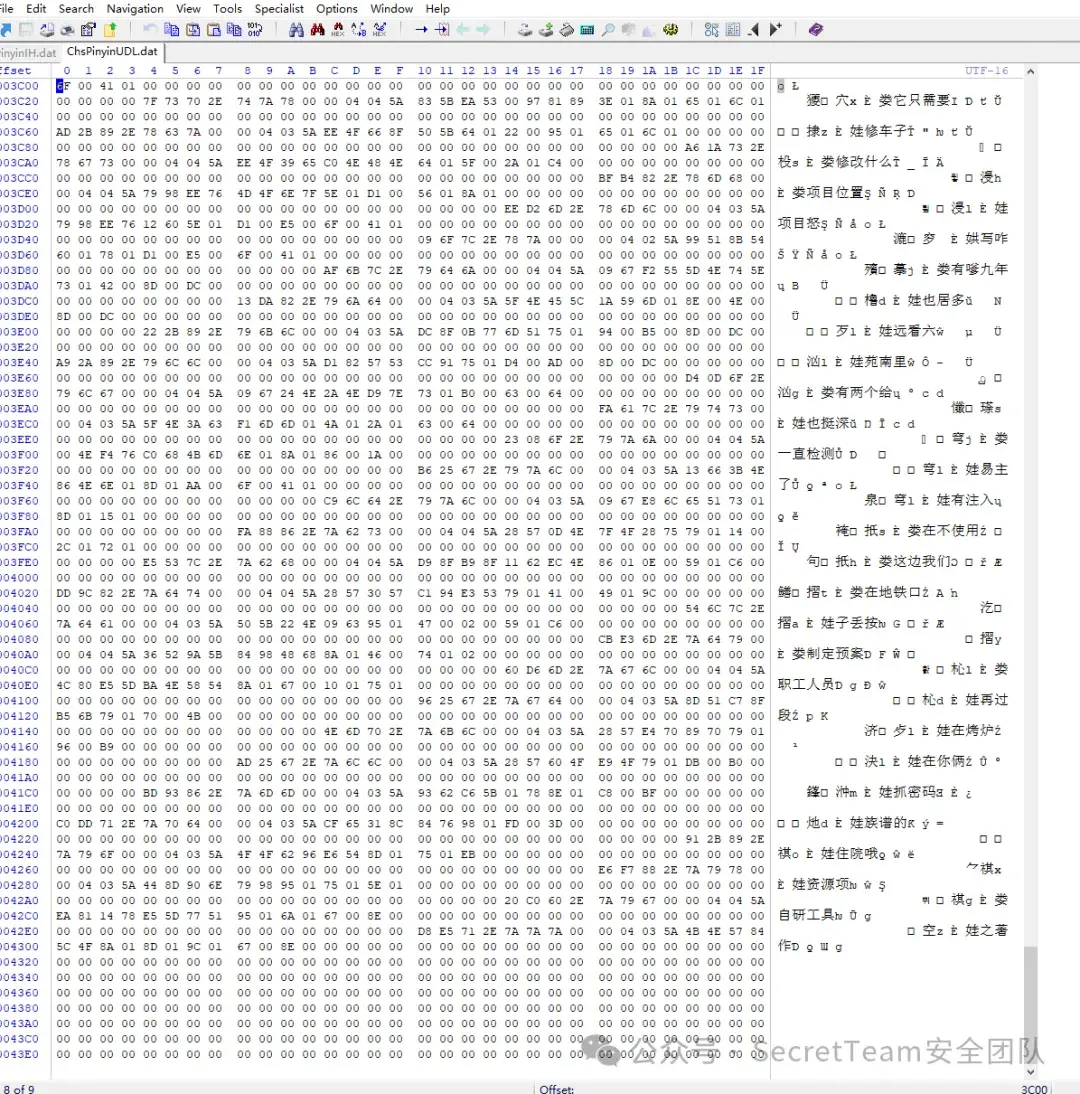
进一步分析ChsPinyinlH.dat和ChsPinyinUDL.dat两文件,发现ChsPinyinlH.dat文件记录着系统用户的中文字词输入信息,而ChsPinyinUDL.dat文件记录着系统用户的中文短句输入信息。
由此可知,Win10中文输入法用户词库信息采用独有格式进行存储,但没有采用复杂的加密算法对其进行保护处理。
逆向分析
因此,依据中文输入法的拼音特性,构建基于输入数据流的逆向分析策略,对词条信息的内部存储数据结构进行分析。具体逆向测试策略如下:
- 初始化用户词库文件信息,分别选定一个单词和短句,用Win10中文输入法各输入一次,其目的是探察两个文件存储输入信息的初始位置。
- 将策略1所选的单词和短句,用Win10中文输入法重复输入一次,其目的是探察同一词句输入次数改变对存储信息的影响。
- 有别于策略2的选择,另选内容不同、字数一样的单词和短句,用Win10中文输入法各输入一次,其目的是探察词句内容的改变对已存储输入信息位置的影响,即获取单个词条存储信息需占用的总长度。
- 有别于之前所有策略的选择,再另选内容不同、字数不同的单词和短句,用Win10中文输入法各输入一次,其目的是探察词句字数的改变对存储信息的影响。同时,结合策略3和策略4对比,内容和字数的改变对存储位置的影响。
依据上述基于数据流的逆向测试策略,对两个DAT用户词库文件进行结构分析,发现ChsPinyinlH和ChsPinyinUDL两个DAT文件存储的输入记录信息数据起始位置分别是在文件偏移地址0x1400处和0x2400处,每条用户输入记录信息的存储长度都是固定的,占用60个字节。
同时,发现ChsPinyinlH.dat文件对用户每条输入行为信息的存储结构主要按如下图所示的固定格式进行存储。
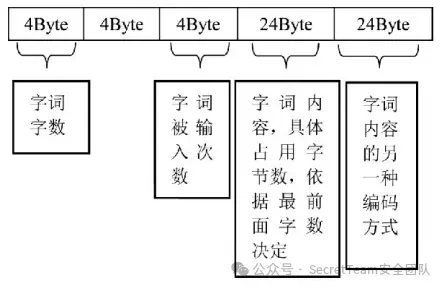
其中关键信息主要在第一部分和第三部分的4个字节以及第四部分的24个字节,第一部分存储此条字词的字数,第三部分存储词条字词被输入的次数,第四部分则存储了此条字词的具体内容。
而ChsPinyinUDL.dat文件对用户每条输入行为信息的存储结构主要按如下所示的固定格式进行存储。其中关键信息主要在第二部分的2个字节和第四部分的48个字节,第二部分存储此条短句的字数,第四部分存储了此条短句的具体内容。
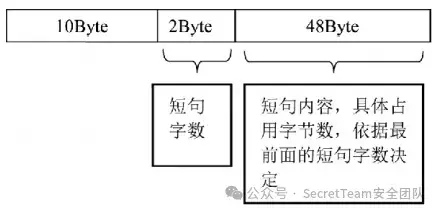
使用python 编写提取代码:
shurufa.py:
import os
# 使用 %USERPROFILE% 获取用户主目录
user_profile = os.getenv("USERPROFILE")
# 处理 ChsPinyinUDL.dat
with open(f"{user_profile}\\AppData\\Roaming\\Microsoft\\InputMethod\\Chs\\ChsPinyinUDL.dat", "rb") as f:
data = f.read()[9216:]
with open("1.txt", "w", encoding="utf-16") as output1:
i = 60
n = 1
results = []
while True:
chunk = n * i
if chunk >= len(data):
break
chunk_len = data[chunk + 12:chunk + 12 + 48]
decoded_str = chunk_len.decode("utf-16")
if decoded_str: # 只写入非空字符串
results.append(decoded_str)
n += 1
output1.write("\n".join(results) + "\n")
# 处理 ChsPinyinIH.dat
with open(f"{user_profile}\\AppData\\Roaming\\Microsoft\\InputMethod\\Chs\\ChsPinyinIH.dat", "rb") as f:
data = f.read()[5120:]
with open("2.txt", "w", encoding="utf-16") as output2:
i = 60
n = 1
results = []
while True:
chunk = n * i
if chunk + 12 >= len(data):
break
unicode_chunk_length = data[chunk] * 2
if unicode_chunk_length > 0 and chunk + 12 + unicode_chunk_length <= len(data):
unicode_chunk = data[chunk + 12:chunk + 12 + unicode_chunk_length]
if unicode_chunk:
results.append(unicode_chunk.decode("utf-16"))
n += 1
output2.write("\n".join(results) + "\n")
使用说明
【1】安装python。
【2】双击shurufa.py。
【3】输出结果为1.txt和2.txt。
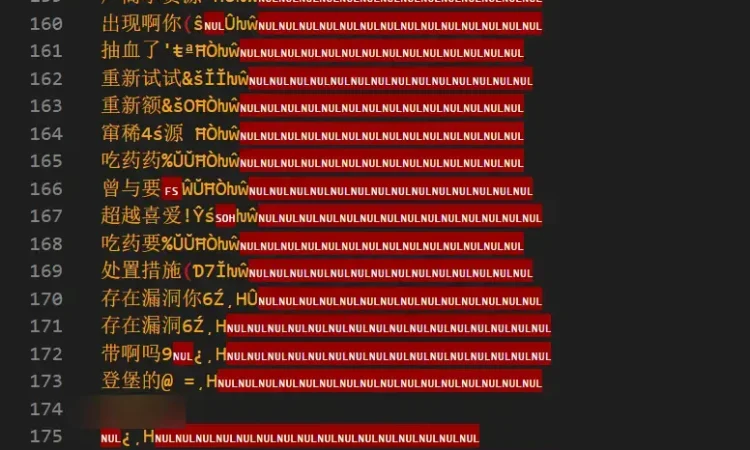
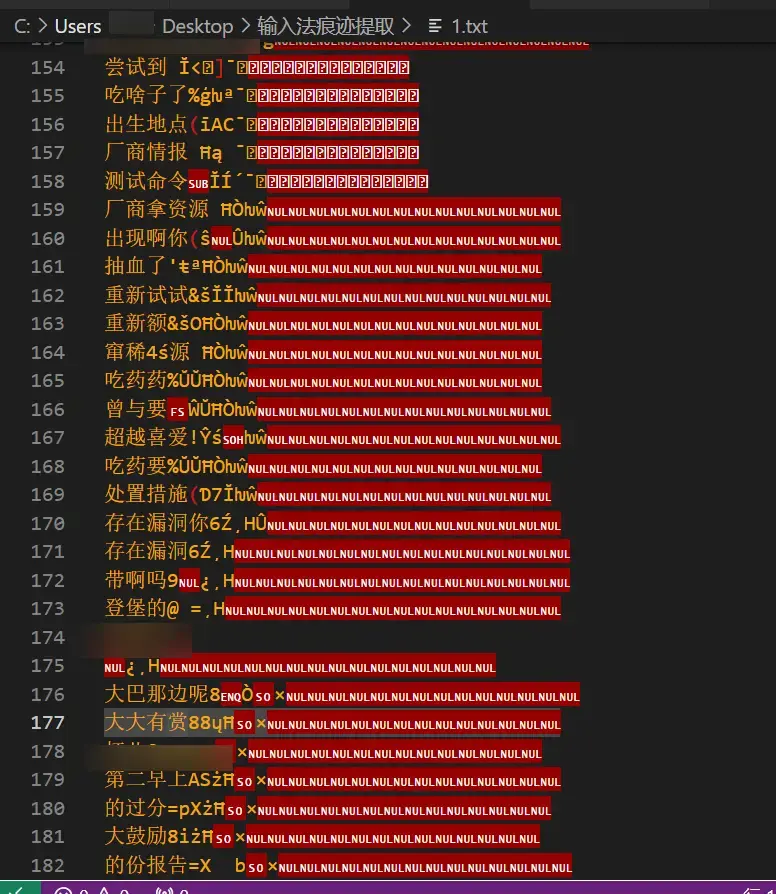
使用截图
from
https://mp.weixin.qq.com/s/RDLcPAPlUnf0Kc5tiYeG7w
转载请注明出处及链接