
目录导航
两年前,我开始了成为更好、全面的安全从业者的旅程,并真正增加了业余项目。无论您是红队、蓝队、紫队、黑客、有抱负的从业者还是经验丰富的专家,都有巨大的机会利用云、自动化和现代技术来跨越信息安全计划和能力。尽管本主题侧重于漏洞赏金,但其原理、示例和底层基础适用于大多数技术领域。
我希望当您阅读本文时,它可以在您自己的角色、职责和研究中激发想法,并为开始了解基于云的生态系统的好处铺平道路。我试图提取相关的代码片段,您可以修改或至少将其用作有用的指南
第 1 部分 – 心理学
首先,这个项目是我从事过的最长的日常工作项目之一。在去年参加了H1-2010 虚拟活动之后,我已经有了,正如STÖK所说的“虫子热”,并将其与我的极端竞争力、不懈的野心、不断学习和对了解几乎所有事情的好奇心结合起来.
此外,我很快意识到我目前的漏洞赏金方法与我想要的结果水平不兼容。在优先考虑家庭、平衡全职工作和维持生活的责任之后,这给我留下了从晚上 10 点到凌晨 1 点左右的时间来进行漏洞赏金挖掘。老实说,有两个年幼的孩子会让人筋疲力尽,所以我发现我通常每周最多可以分配 4 天,因为我仍然需要睡眠。每周大约有 12 个小时,我陷入了一个固定的循环,我将其称为漏洞赏金困境:
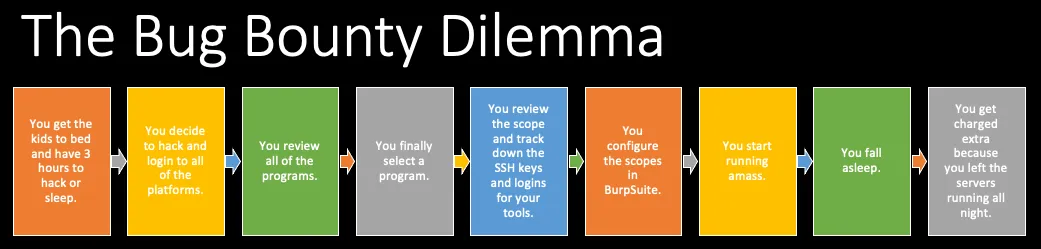
这种非生产性的循环继续下去,我决定我需要改变方法。
客观的
建立一个可扩展、经济高效、基于云的平台,该平台完全自动化漏洞赏金计划侦察,将原始数据转化为可操作的情报。
整个基于云的平台需要一个包含程序名称和预期操作的 API 调用,它将启动自动侦察过程并输出可用的文件、图表和仪表板,以研究潜在的漏洞。
原则
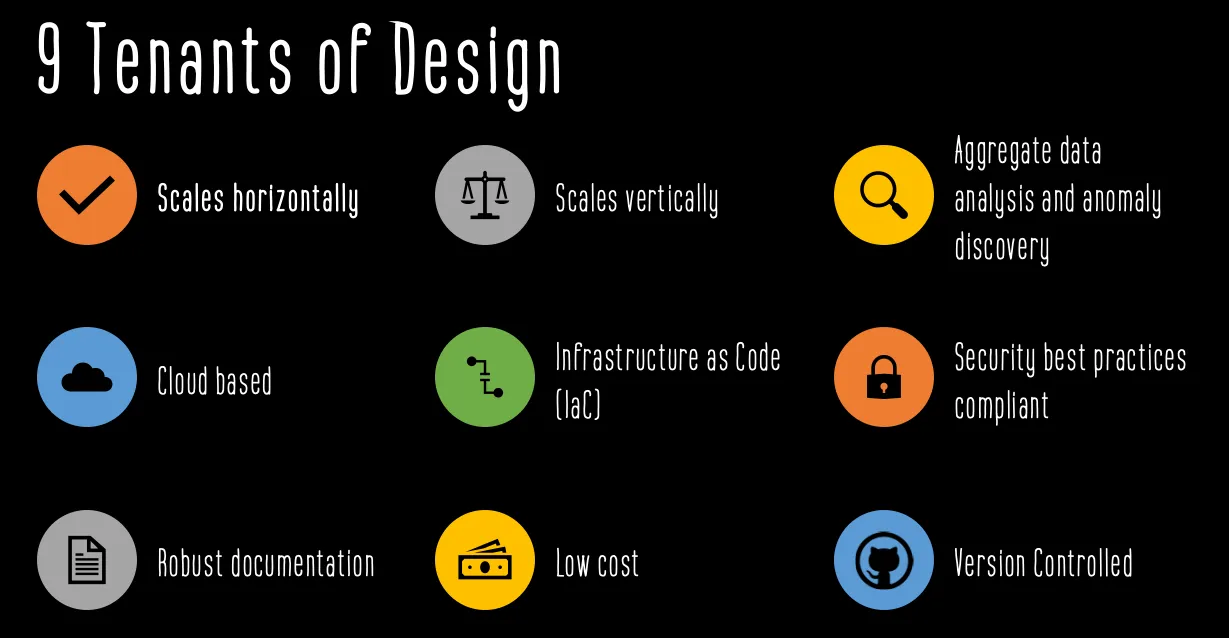
- 一个水平扩展以支持所有可用漏洞赏金计划的框架。
- 一个支持模块化组件以不断增加深度的框架。深度可能包括新工具、错误类或广泛的自动检查。
- 跨所有程序的数据分析可以突出异常,识别跨程序的类似配置,并递归地利用输出。
- 100% 基于云,不依赖个人设备。
- 编码基础设施即代码 (IaC),以便环境可重用、尽可能短暂、可重新部署和动态生成。
- 环境必须符合安全最佳实践(即源代码中没有秘密、最低权限以及传输和静态数据加密)。
- 清晰的输入、输出、代码注释和总体目标的强大文档。
- 基础框架需要最小的成本。最好,基本功能成本由一个低严重性的赏金支付(云成本低于 250 美元/月?)。
- 版本控制对于保持代码连续性、避免意外代码丢失以及与行业共享至关重要。
参考架构
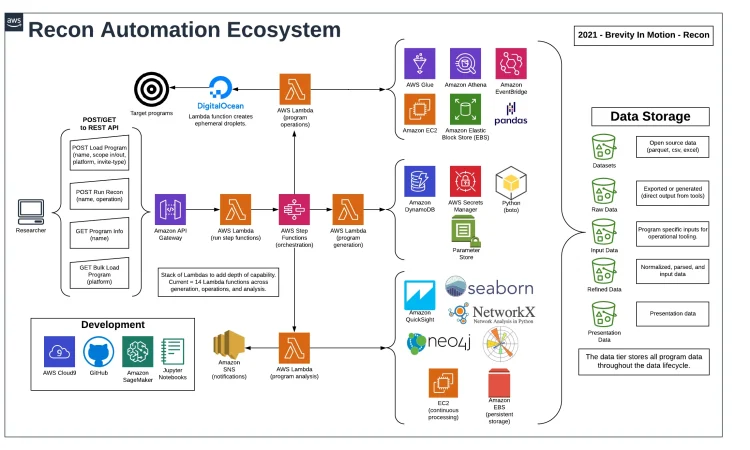
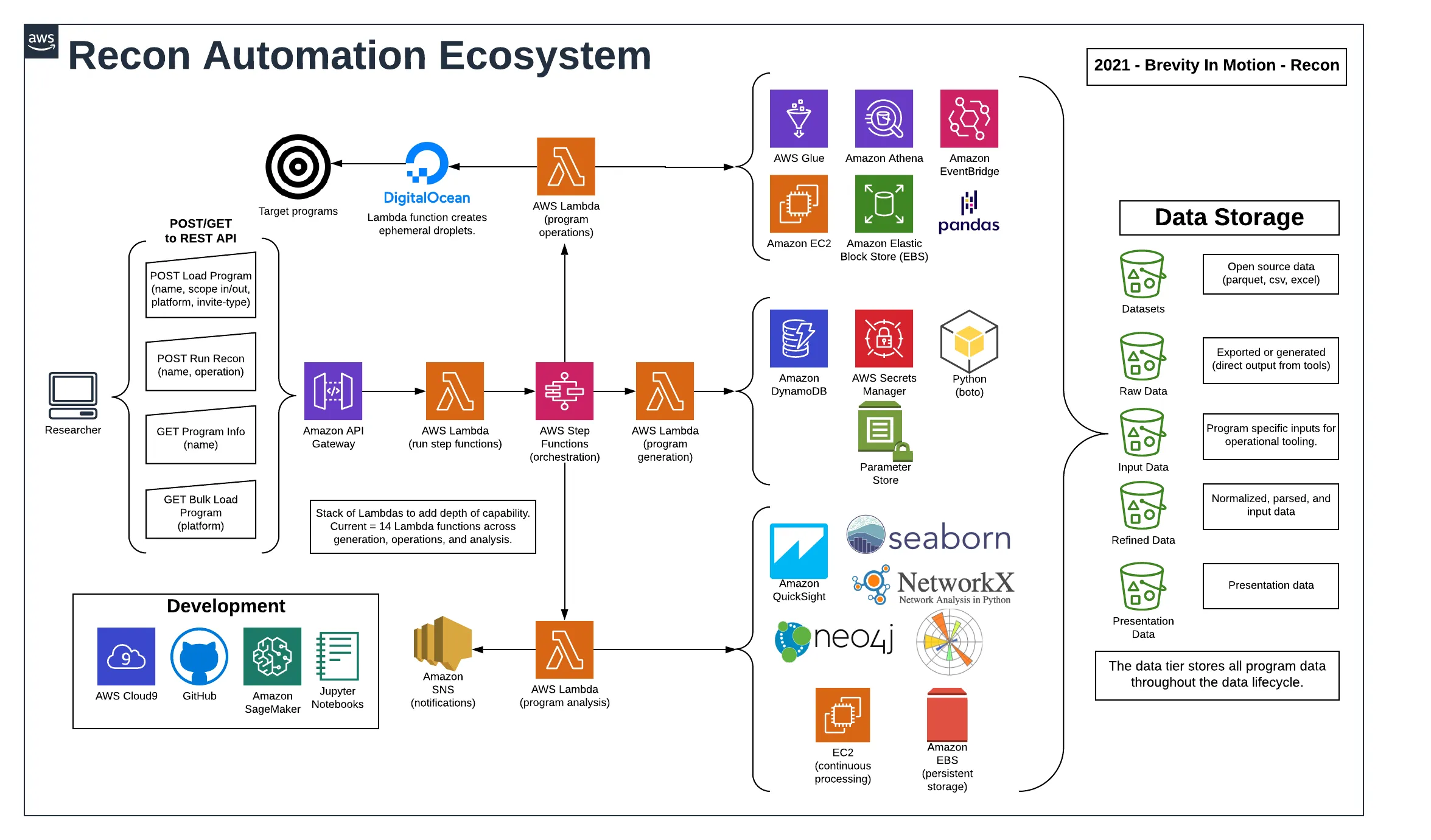
该平台利用多种云原生服务,交织在一起提供模块化数据产品,这些产品经过处理并转化为可操作的智能。
参考架构包含模块化为三个主要自动化类别的组件。
- 程序生成– 漏洞赏金计划的管理、维护和跟踪。
- 程序操作– 技术侦察功能,例如对第三方数据源的 API 调用、DNS 枚举、网络爬虫、端口扫描和网络模糊测试。
- 程序分析– 处理操作的原始输出,为递归操作准备数据输入,规范化数据以进行可视化和报告,以及通过数据关联创建智能程序。
流程概览
本文稍后将更详细地描述这些过程中的每一个。
- 程序既可以从平台集成中批量加载,也支持手动加载程序。
- 静态程序信息存储在 DynamoDB 数据库中。
- 操作通过 API Gateway GET 和 POST 请求启动。
- 请求被代理到初始 Lambda 函数。
- Lambda 启动 Step Functions 状态机,参数定义预期的工作流路径。
- 操作是使用 Step Functions 编排的。
- 每个操作都有自己的 Lambda 以最小化复杂性。
- 主动操作是使用短暂的数字海洋水滴启动的。
- 环境特定变量存储在 AWS Parameter Store 中,而 API 密钥和凭证存储在 AWS Secrets Manager 中。
- 所有生成的数据都存储在 S3 中。
- Python Pandas DataFrames 用于处理和清理数据。
- 输出通过 AWS QuickSight 进行汇总和查看。
- 视觉关系是使用 GraphDB 技术生成的。
- 数据使用 AWS Glue 编制索引并使用 AWS Athena 进行搜索。
- 初始开发在 SageMaker Jupyter Notebooks 中执行以建立新功能。
- 稳定开发在 AWS Cloud9 IDE 中执行,并在部署之前合并到 Python 包中。
- 所有源代码都在 GitHub 存储库中存储和管理。
参考架构详情
1. 程序既支持平台集成批量加载,也支持手动加载程序。
第一步是跨主要漏洞赏金平台导入和加载程序。未来的更新将侧重于直接平台集成。但是,批量加载功能目前正在使用来自 Arkadiy Tetelman 的 GitHub 存储库 ( https://github.com/arkadiyt/bounty-targets-data ) 的数据,该存储库每小时更新一次。感谢 Arkadiy 开发和发布的宝贵资源!自动化的批量加载功能利用了存储库中的原始数据文件。
批量加载是使用 AWS Lambda 函数启动的。它利用 Pandas DataFrames 来存储、规范化数据并将其加载到 DynamoDB 表中。以下是 Lambda 函数的示例。
被调用的附加函数与作用域解析有关。为了成功实现自动化,范围的每个变化都需要通过代码进行处理。本文的挑战部分描述了有关此问题的进一步背景。代码和解析尚不完美,但可以处理大多数变体。
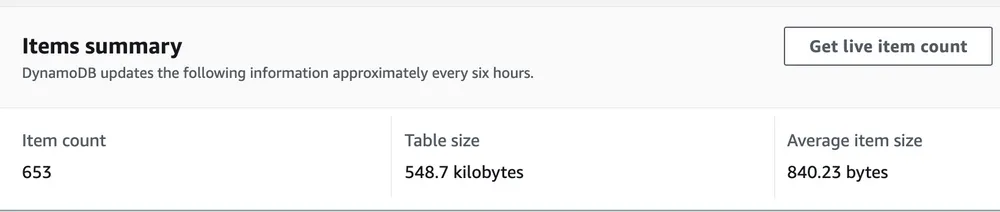
2. 静态程序信息存储在DynamoDB 数据库中。
每个程序都被加载并存储到一个 DynamoDB 表中。仍然需要添加其他程序,但它目前有 653 个程序可用于启动侦察。
将程序加载到 DynamoDB 的示例代码(非整体)是:
相同的通用函数可用于手动、单独的程序加载,并且可以通过结合 Lambda 函数的 AWS API 网关加载。
可以使用以下有payload启动 POST 请求。
接收 post payload的 Lambda 部分是:
将程序加载到 DynamoDB 后,它们就可以在自动侦察操作中使用了。
3. 操作通过 API Gateway GET 和 POST 请求发起。
AWS API Gateway 提供的易用性和灵活性使其成为一项极其有价值的自动化服务(AWS API Gateway 文档)。

AWS API Gateway 支持基于 REST 的 url 结构,其中可以针对定义的路径提交请求。此外,可以通过 POST 和 GET 请求提供参数。每个路径都可以映射到不同的 Lambda 以直接通过 API 公开函数。
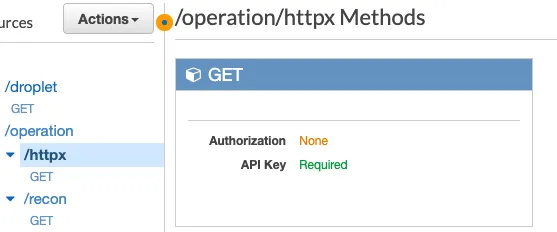
主路径是 /operation/recon,它接受两个参数:程序名称和预期的操作。
发起请求看起来像:
curl -X GET -H "x-api-key: fakeapikeyvalue" -H "Content-Type: application/json" "https://api.brevityinmotion.com/operation/recon?program=tesla&operation=initial"尽管屏幕截图显示应用未授权(并将在稍后阶段交付),但 API 网关配置为需要有效的 API 令牌进行身份验证。为 API 配置身份验证很重要,否则,唯一的安全形式将基于 URL 中的 API ID(如果使用自定义域名,该 ID 也会消失)。API 密钥值作为标头值“x-api-key”传递(以上面的 curl 命令为例)。
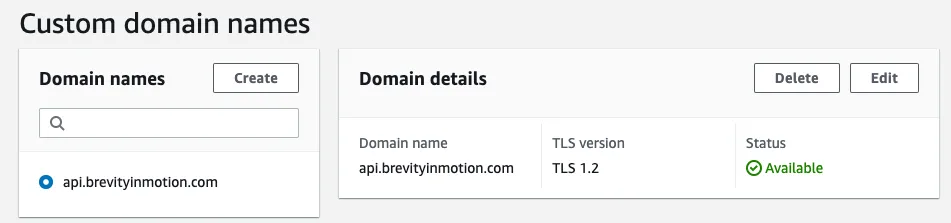
API 网关支持自定义域名,可以在服务的“自定义域名”部分进行配置。它需要在权威区域记录中添加条目并将证书应用于 API,并且可以使用 AWS Certificate Manager (ACM) 服务快速生成。
4. 请求被代理到初始 Lambda 函数。
API 网关可以配置为将(代理)流量直接传递到 AWS Lambda 函数。这增加了将带参数的 Python 函数转换为带参数的 API 调用的便利性;需要少于 5 分钟的配置。

5. Lambda 启动 Step Functions 状态机,参数定义预期的工作流路径。
接收 Lambda 函数的代码库最少,主要目的是捕获 API 参数并将它们作为变量传递给 AWS Step Functions 服务。
6. 操作使用 Step Functions 进行编排。
AWS Step Functions 工作流程的初始输入包括程序名称和操作。可以在 Step Functions 中添加选项以绕过步骤或直接转到特定操作以响应提供的操作参数。
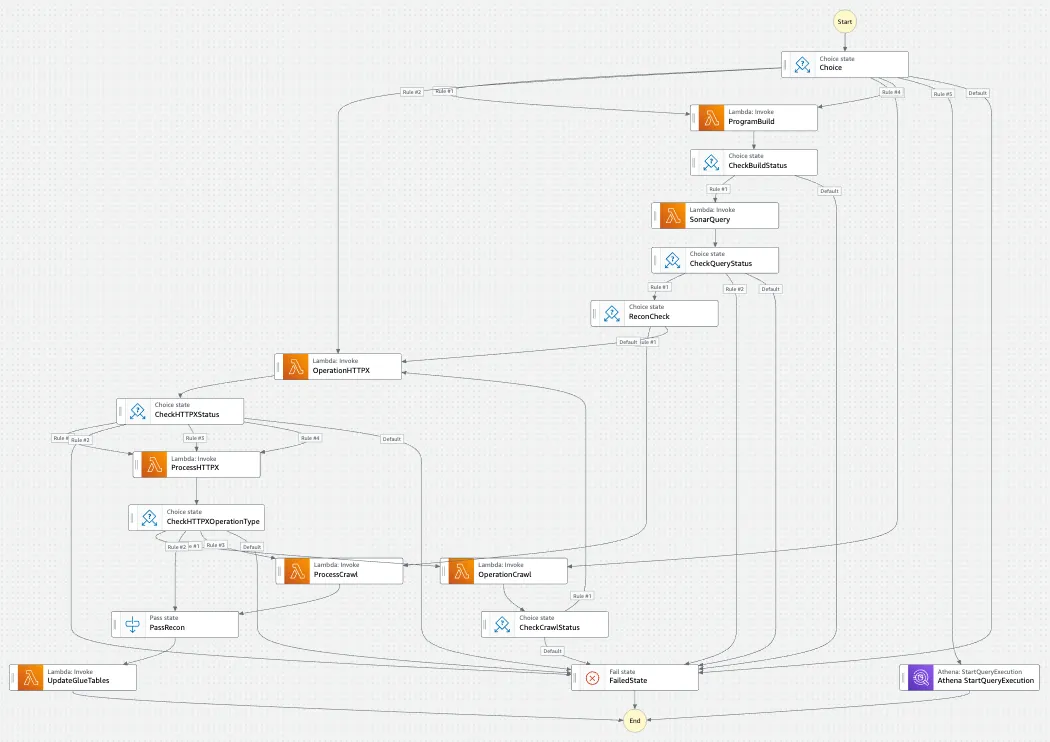
Step Functions 是用于编排工作流、使用回调提供带外流程、启动其他原生 AWS 服务以及启动相关通知的强大工具。它是极其模块化的,可以在开发时添加新功能。
有关 Step Functions 使用、优势和方法的其他信息,
请访问
breviityinmotion.com/aws-step-functions-to-accelerate-bug-bounty-recon-workflows
通过复制这种方法,它能够转换 Python 代码或 AWS Lambda 支持的任何其他功能,并使其可作为 API 调用。这对于无限量的用例来说非常强大。
7. 每个操作都有自己的 Lambda 以最小化复杂性。
通过遵循 Daniel Miessler 在他的Mechanizing the Methodology演讲中分享的许多模块化原则,没有工具管道。工作流的每个组件都有一个功能要执行。尽管管道很大(这里有一些诱人的例子)很诱人,但每个组件都被隔离,并且模块化使故障排除更容易。
通过这种方法,可以重用数据,可以监控程序,并且可以根据数据驱动的决策定制开发。操作仍然利用输入/输出管道,但链接是在对工具的原始输出进行后处理之后。后处理为生成的数据工件添加了额外的元数据、相关性和洞察力。例如,这里有一个特定于Project Discovery 的 httpx软件的脚本,它生成特定于程序的 shell 脚本、安装软件、标准化输出并将其加载到 S3 中。
8. 使用短暂的 Digital Ocean Droplets 启动主动操作。
一些编排步骤启动针对程序的主动侦察。所有主动侦察都是从短暂的数字海洋液滴中进行的。
每个侦察操作都有一个专用的 Lambda 函数来执行任务。Lambda 函数动态生成启动脚本以安装适用的工具,为工具生成程序特定的配置文件,并调用 Digital Ocean API 创建一个 Droplet 并运行启动文件。
如果需要直接在 droplet 服务器上调试和监控输出,则连接到 droplet 时进行监控的命令是:
Lambda 生成安装本地工具的脚本。为了让 Droplet 建立与 AWS S3 存储桶的连接,Lambda 从 AWS Secrets Manager 中提取访问密钥/秘密密钥并将其写入脚本。即时方法具有巨大的价值,因为秘密令牌可以集中和定期轮换,同时自动合并到工作流程中。生成 userdata 启动脚本以构建目录结构,然后使用 AWS cli 从 S3 下载唯一生成的操作脚本。
所有功能都在启动脚本的范围内启动和运行,因此它主要是一个执行更多脚本的脚本。在执行预期操作和任何必要的数据处理后,操作的输出将上传到原始和精炼的 S3 存储桶。
上传所有数据后,启动脚本的最终命令是关闭 Droplet。AWS 中有一个 Lambda 函数可以对 Digital Ocean API 进行查询,如果任何 Droplet 处于“关闭”状态,它们就会被销毁。在某些时候,需要根据命名约定添加过滤功能,以便它不会意外删除其他不相关的 Droplet。AWS EventBridge 服务维护每 5 分钟运行一次此 Lambda 的临时 (cron) 作业,因此永远不会出现处于关闭状态超过 5 分钟的临时 Droplet,这支持成本原则。
9. 环境特定变量存储在 AWS Parameter Store 中,而 API 密钥和凭证存储在 AWS Secrets Manager 中。
Amazon 提供了两种用于持久存储变量的服务,并且都具有用于编码检索的 API。AWS Secrets Manager 可用于存储秘密值,并且是 Digital Ocean API 密钥、Amass 配置文件 API 密钥和 AWS 访问密钥/秘密密钥的存储位置。借助 API 集成的简便性,可以检索秘密并将其用于即时 (JIT) 设计原则。
此示例代码的一部分直接取自 AWS 控制台中的预制代码。
对于配置变量的持久存储,使用了 AWS Parameter Store(AWS Systems Center 的一部分)服务。Parameter Store 的成本要低得多,并且可以类似地扩展以满足用例。示例参数包括存储桶名称和步骤函数 arns。
每个 Lambda 函数通常以检索执行任务所需的任何适用变量的函数开头。
10.所有生成的数据都存储在S3中。
数据层是整个自动化平台的关键组件。数据分为以下几类:
- 数据集– 包含从外部来源聚合的数据集副本的存储桶,这些副本可能无法直接访问或集成。示例包括MaxMind数据库和 csv 文件的下载。
- 输入数据– 随着程序的生成,任何配置文件和 shell 脚本都被加载到 input/<program>/<files> 的文件路径中。这些文件在运行时从程序目录级别复制到临时操作和本地运行的服务器或容器。
- 原始数据– 此存储桶包含工具的原始输出。此外,所有原始 Web 响应都存储在存储桶中。原始数据存储桶使用 aws 同步命令同步到持久性 EC2 服务器。随着新功能、关键字和功能的添加,此持久服务器始终可以跨新数据或跨整个数据运行搜索。当前方法使用sift (keyword/regex search)、semgrep (static code analysis)和核模板(使用 –passive 标志)。
- 精炼数据– 此存储桶包含从工具建立的后处理输出文件。这可能是包含添加字段的文件,例如程序名称、基本 URL 或聚合/组合数据。
- 演示数据– 此存储桶包含已格式化并准备用于报告和仪表板的文件。任一流程都使用 Seaborn、Matplotlib 和 NetworkX 等库直接利用数据生成图表和图形,或者用作数据呈现工具(AWS QuickSight、AWS Glue、Neo4j)可以直接指向存储库的位置。
11. Python Pandas DataFrames 用于处理和清理数据。
Python Pandas 库是一个强大的数据分析库,被数据科学家广泛使用。有关使用 Pandas 的其他示例,请参阅brevityinmotion.com/external-ip-domain-reconnaissance-and-attack-surface-visualization-in-under-2- 上使用 Rapid7 Sonar 数据集的演练分钟/使用 Jupyter 笔记本。
Python Pandas 可以将各种文件类型(包括 .csv 和 .json 文件)加载到称为 DataFrame 的内存数据结构中。它可以被操纵、转换和重塑以增强或增加初始数据。它还可以直接与 S3 存储桶集成。最后,它可以将数据输出回 .csv 或 .json 文件。在为 GoSpider 站点抓取准备 HTTPX 输出时,HTTPX 输出会加载到 Pandas DataFrame 中并为 GoSpider 做准备。
这是加载原始 JSON HTTPX 输出、添加程序名称、解析 URL 字段以添加 baseURL 列,然后将其作为 JSON 文件输出回 S3 的示例用例。
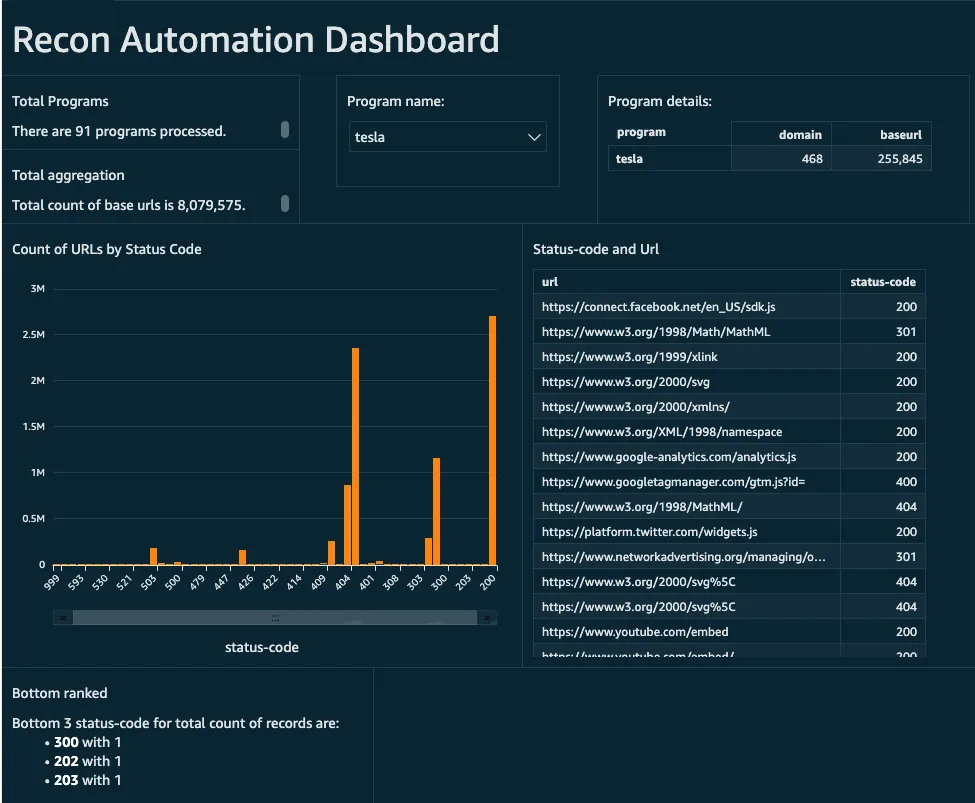
12. 通过 AWS QuickSight 汇总和查看输出。
AWS QuickSight 是一个强大的仪表板和报告功能,可以将精炼数据转换为超快速、并行、内存中计算引擎 (SPICE) 数据。
仪表板是可定制的,可以显示各种视图、数据元素和过滤查询。以下是一些使用 HTTPX 输出数据的示例仪表板。
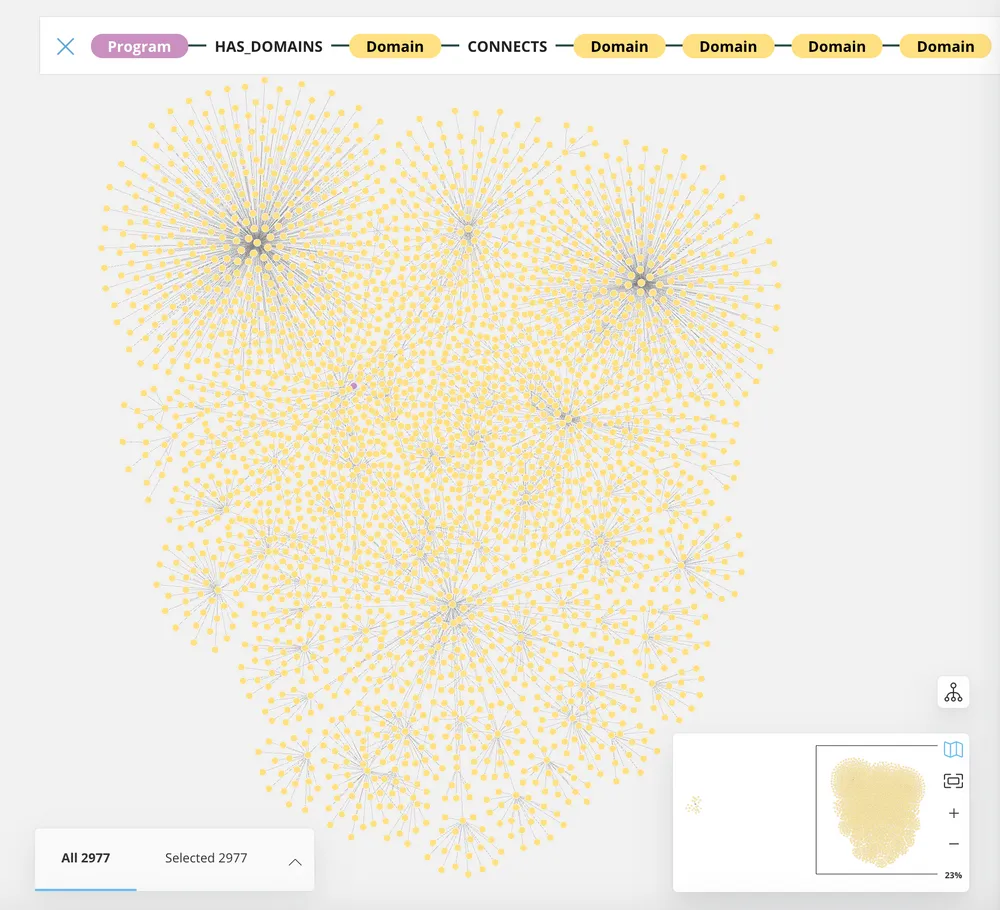
13.使用GraphDB技术生成视觉关系。
为此开发的初始可视化是使用 AWS Neptune。但是,由于 Neptune 可视化的一些限制,它被替换为通过 Google Cloud 销售的第三方 PaaS Neo4j 托管图形服务。它提供了程序、域、IP 地址、URL 和 ASN 之间的强大关系映射。
由于大规模的成本问题,它还没有得到广泛的成熟和集成,但最底层的选项对于分析和可视化单个或少数程序是有效的。通过将欺诈分析类型技术应用于发现异常或项目之间共享依赖项和第三方库,这最终将成为一个更大的焦点。Neo4j 的代码示例将在以后进一步成熟时共享。
为了至少建立一些图形功能,可以在Jupyter笔记本中利用NetworkX与Bokeh 的结合来针对单个程序运行临时分析。
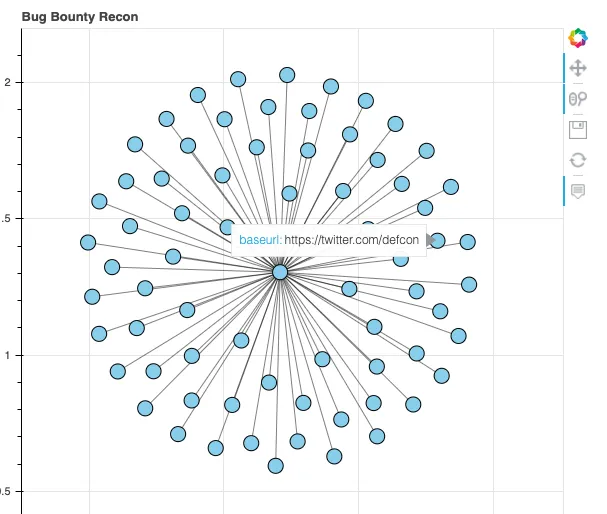
可以利用和改编的代码是:
14. 数据使用 AWS Glue 编制索引并使用 AWS Athena 进行搜索。
另一个用于数据处理的强大工具/服务是 AWS Glue 的组合,用于索引文件和使用 AWS Athena 搜索索引数据。在数百个程序中快速运行多种工具会导致输出文件过载,管理和搜索可能会不堪重负。
AWS Glue 非常接近于为数据存储库编制索引的点击式解决方案。它可以指向 S3 目录路径并递归索引类似的文件类型。例如,数百个 HTTPX 输出 json 文件可能存储在以下结构中:
- S3://bucketname/httpx/programA/httpx-output.json
- S3://bucketname/httpx/programB/httpx-output.json
- S3://bucketname/httpx/programC/httpx-output.json
Glue 爬虫可以指向 S3://bucketname/httpx/* 路径,它将爬取文件,自动发现列,并生成一个可搜索的表以供 Athena 使用。
加载了 91 个程序后,就有超过 1000 万个带有可搜索和索引的相应元数据的 url。
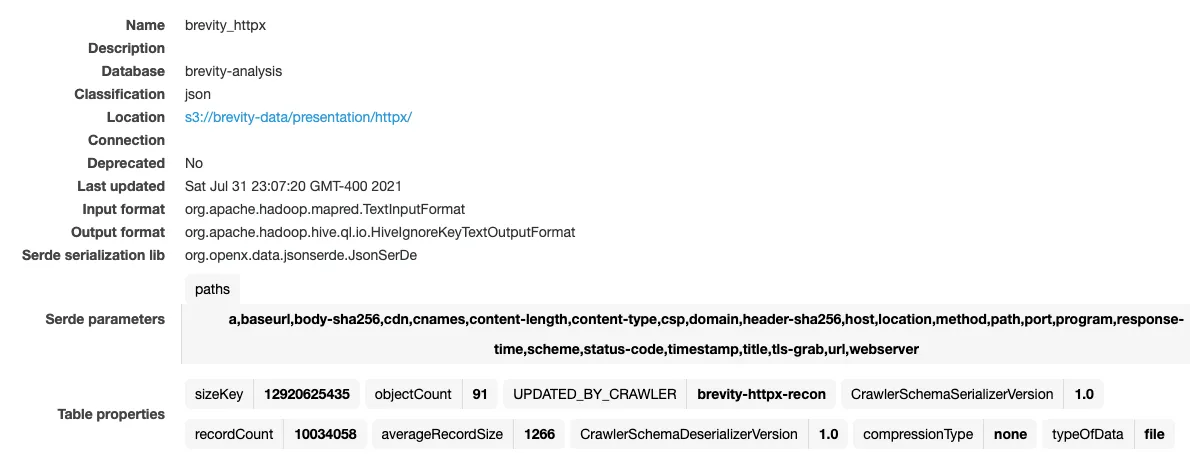
在每个侦察工作流完成时,Glue 爬虫启动以更新表格,为数据分析做准备。
表更新后,可以在 AWS Athena 中使用Presto 语法搜索文件。下面是一个示例查询。每个查询也可以通过 API 启动,并将结果写入定义的 S3 存储桶位置。
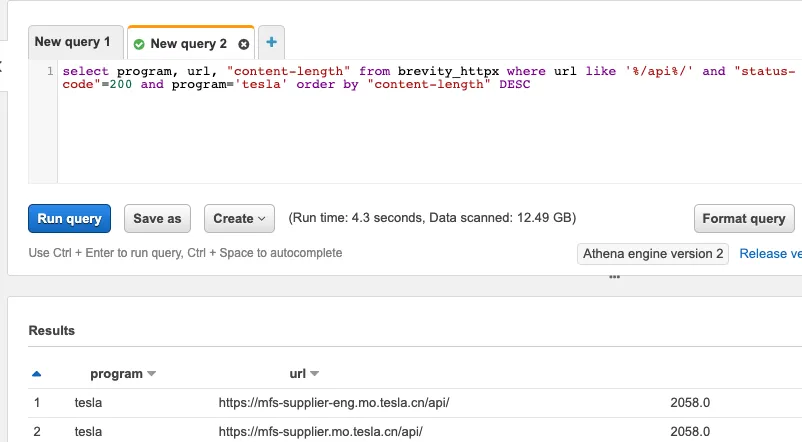
例如,一个用例可能是在每个程序中查询特定 URL 路径或 Web 服务器类型的所有 URL,然后将 baseURL 列表输出到 S3 存储桶。然后,诸如Nuclei 之类的扫描工具可以利用结果作为输入文件来针对已识别的目标运行适用的模板。这遵循将 1000 万个随机 URL 转换为更有限的子集的目标,这些子集具有更高的发现漏洞的可能性。这不仅可以更有效地利用漏洞发现,还可以减少对程序的干扰量,同时增加研究人员发出信号的可能性。
15. 在 SageMaker Jupyter Notebooks 中进行初始开发以建立新功能。
在云环境中进行开发时,利用Jupyter notebooks已成为调试、故障排除和广泛的原生云服务集成的加速器。这对于初始开发环境来说可能并不常见,并且在将代码移植到更强大的 IDE 中时确实会导致一些技术债务,但它使得开发快速集成、可扩展的内存数据分析或对于某些人来说变得非常容易试图提高他们使用 Python 等语言或使用 API 的技能。由于 Jupyter Notebook 可以将代码分解为可以独立运行的单个单元格(类似于调试器断点),因此解决代码中的错误非常容易。
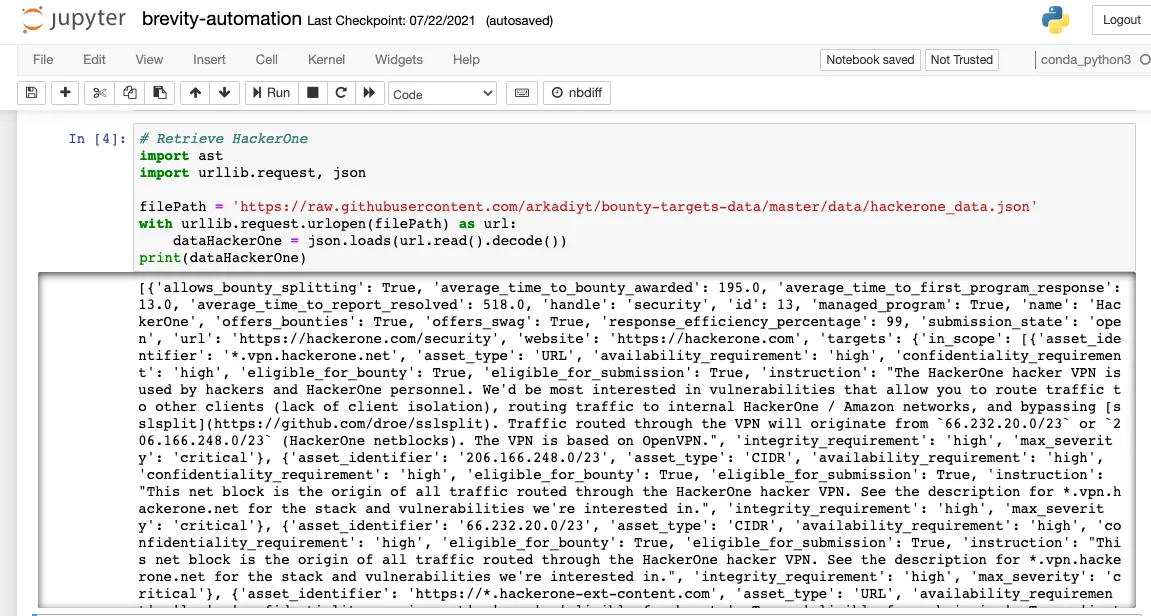
在 AWS 生态系统中工作时,AWS SageMaker 服务提供托管的 Jupyter 笔记本环境。与其他 AWS 服务集成时,它消除了处理身份验证和授权的挑战,因为它可以使用分配的执行 IAM 角色运行;从而消除了在代码中管理访问的需要。缺点是,如果持续运行,这种环境可能会很昂贵。

Google Cloud 提供免费的托管 Jupyter Notebook 环境,是进行调查的不错选择 ( http://colab.research.google.com/ )。

对于本地安装,Anaconda 是一种流行的基于 Jupyter 的开源数据科学工具包 ( https://www.anaconda.com/products/individual )。

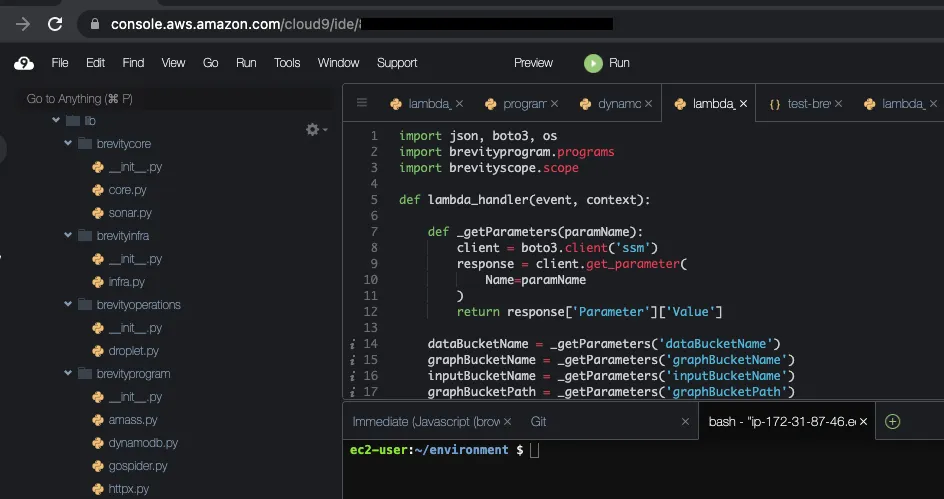
16. 稳定开发在 AWS Cloud9 IDE 中执行,并在部署之前合并到 Python 包中。
随着代码库的增长并需要在具有 linting 和 GitHub 集成等功能的更强大的开发 IDE 中进行管理,它被迁移到 AWS Cloud9 工作区。原则之一是避免任何个人设备依赖(访问浏览器除外),Cloud9 已被利用。它是一个基于浏览器的 IDE,支持持久存储,在超时期间自动关闭以节省成本,并包含一个命令行。到目前为止,Cloud9 完美地支持了该项目。与 SageMaker 中的 Jupyter 笔记本类似,Cloud9 IDE 支持在实例配置文件下运行,该配置文件提供跨 AWS 生态系统的访问和授权。这在使用 cli 进行部署或测试代码集成时很有用。
17. 所有源代码都在 GitHub 存储库中存储和管理。
为了保持弹性、连续性并避免数据丢失,所有代码都在 GitHub 中存储和管理。它目前位于一个私有存储库中,但在即将于 8 月 7日举行的DEF CON 29 Recon Village 演示之后,大部分代码将迁移到开源公共存储库。
克服的挑战/吸取的教训
随着语法、秘密和范围的发展,很难使脚本和程序保持最新。
解决方案 – 通过缩小生成和运行时之间的差距来利用即时 (JIT) 模型。
- 工具和技术的输入文件在运行时生成,而不是存储预先生成的脚本和命令。
- 使用 JIT 方法,可以在一个位置维护命令语法,并且可以在操作执行之前立即写入程序名称、范围和机密等变量。
基于对象的存储解决方案(即 S3)很难在非结构化和半结构化数据中进行搜索。
解决方案 – 运行持久性 EC2 服务器,该服务器运行 S3 同步 cli 命令以在 EBS 存储卷上维护 S3 存储桶文件的副本。这似乎也是最具成本效益的选择。尽管它将 S3 数据复制到 EBS,但可以对数据应用的不间断处理、搜索和分析量最终应该具有一致的投资回报 (ROI)。
文件和程序应该如何组织?
解决方案 – 尽可能用每个程序一个目录分隔程序,然后将它们组织在相同的目录结构中。整体指标的某些情况需要保持在同一路径内,但仍可以由目录分隔。
- 如果每个程序没有目录,将程序文件拉到超出预期范围和操作的临时系统时就会出现问题。
- 如果未通过程序、域、操作等分离原始数据和输出,则会出现目录中文件过多的问题。
保持跨自动化的范围很困难
有许多不同的方式可以定义和阐明范围。越来越多的变体必须被编程到自动化中。发生且必须处理的变化示例。
- https://site.com/inscope
- site.com/inscope
- .site.com
- https://site.com/inscope/*
- <bughunterdomain>.site.com
- 192.168.0.1/16
- 192.168.0.45
- https://github.com/inscoperepo
- com.application.id
- Unstructured text describing scope这些范围内示例也类似于范围外的定义方式。
解决方案 – 每次生成新数据时,检查意外超出范围或损坏功能的输出。继续为变体添加处理和逻辑,涵盖范围内和范围外。
结论
尽管这不是构建生态系统的分步教程,但目标是提供大量成功的示例、想法和策略。尽管漏洞赏金社区竞争异常激烈,但我们最终都在朝着提高全球软件和系统安全性的同一目标努力。
当然,与我联系,如果您有疑问或发现在应用这些概念,你自己的具体使用情况下的成功。随着自动化系统的发展,本文将继续更新。
源代码将在https://github.com/brevityinmotion/brevityrecon公开并提供。

源码下载地址
①GitHub:
github.com/brevityinmotion.zip
②云中转网盘:
yunzhongzhuan.com/#sharefile=F9fuZ39p_14001
解压密码: www.ddosi.org