
目录导航
GoSpider简介
GoSpider是一个使用Go语言编写的快速网络资源蜘蛛爬取工具,主要在侦察工作中用来抓取网站url,AWS-S3,子域,文件等敏感信息.
GoSpider特色
- 快速的网络爬行抓取
- 暴力解析sitemap.xml
- 解析robots.txt
- 从 JavaScript 文件生成并验证链接
- 链接查找器
- 从响应源中查找 AWS-S3
- 从响应源中查找子域
- 从 Wayback Machine、Common Crawl、Virus Total、Alien Vault 获取 URL
- 格式输出可使用正则表达式
- 支持burp输入
- 并行抓取多个站点(多线程)
- 随机移动/网络用户代理
安装方法
GO111MODULE=on go get -u github.com/jaeles-project/gospider
kali安装方法:
apt install gospider -ygospider参数列表
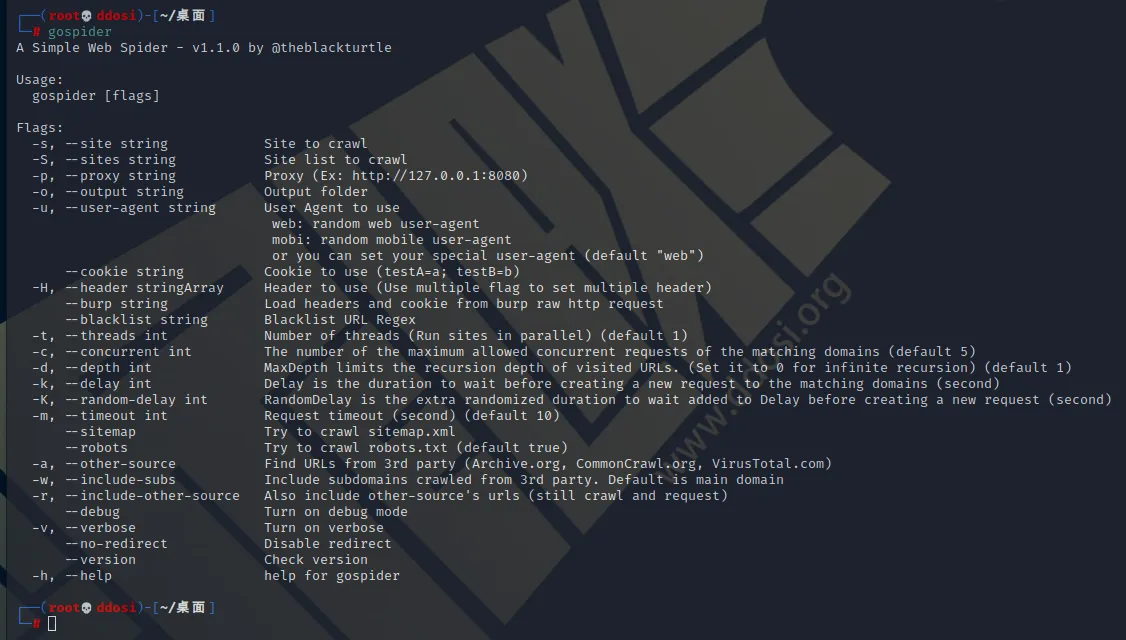
用法:
gospider [flags]
Flags:
-s, --site string 要抓取的网站
-S, --sites string 要抓取的网站列表
-p, --proxy string 代理 (例如: http://127.0.0.1:8080)
-o, --output string 输出目录
-u, --user-agent string 使用user-agent
web: 随机网站user-agent
mobi: 随机手机user-agent
或者您可以设置您的特殊用户代理(默认 "web")
--cookie string 要使用的 Cookie (testA=a; testB=b)
-H, --header stringArray 要使用的标头 (使用多个flag来设置多个标头)
--burp string 从 burp 原始 http 请求加载标头和 cookie
--blacklist string URL黑名单正则表达式
--whitelist string URL白名单正则表达式
--whitelist-domain string 白名单域名
-t, --threads int 线程数(默认为1)
-c, --concurrent int 匹配域的最大允许并发请求数(默认为 5)
-d, --depth int 限制访问过的 URL 的递归深度。(将其设置为 0表示无限递归)(默认为 1)
-k, --delay int Delay 是在创建对匹配域的新请求之前等待的持续时间(秒)
-K, --random-delay int RandomDelay 是额外的随机时间,以等待加入延迟创建一个新的请求之前(秒)
-m, --timeout int 请求超时(秒)(默认为10)
-B, --base 禁用所有,并且只使用HTML内容
--js 在javascript 文件中启用linkfinder(默认为 true)
--subs 包括子域
--sitemap 尝试抓取 sitemap.xml
--robots 尝试抓取 robots.txt(默认为 true)
-a, --other-source 查找来自第三方的 URL(Archive.org、CommonCrawl.org、VirusTotal .com, AlienVault.com)
-w, --include-subs 包括从第 3 方抓取的子域。缺省值是主域
-r, --include-other-source 也包括其它源'小号网址(静止抓取和请求)
--debug 打开调试模式
--json 启用JSON输出
-v, --verbose 显示详细信息
-l, --length 打开长度
-L, --filter-length 打开长度过滤器
-R, --raw 打开原始数据
-q, --quiet 禁止所有输出,只显示 URL
--no-redirect 禁用重定向
--version 检查版本信息
-h, --help gospider的帮助信息gospider使用方法示例
彻底输出
gospider -q -s "https://www.ddosi.org/"单站点运行
gospider -s "https://www.ddosi.org/" -o output -c 10 -d 1批量站点列表运行
gospider -S sites.txt -o output -c 10 -d 1同时运行 20 个站点,每个站点 10 个机器人
gospider -S sites.txt -o output -c 10 -d 1 -t 20还可以从第 3 方(Archive.org、CommonCrawl.org、VirusTotal.com、AlienVault.com)获取 URL
gospider -s "https://www.ddosi.org/" -o output -c 10 -d 1 --other-source还可以从第 3 方(Archive.org、CommonCrawl.org、VirusTotal.com、AlienVault.com)获取 URL 并包含子域
gospider -s "https://www.ddosi.org/" -o output -c 10 -d 1 --other-source --include-subs使用自定义标题/cookie
gospider -s "https://www.ddosi.org/" -o output -c 10 -d 1 --other-source -H "Accept: */*" -H "Test: test" --cookie "testA=a; testB=b"
gospider -s "https://www.ddosi.org/" -o output -c 10 -d 1 --other-source --burp burp_req.txt黑名单网址/文件扩展名。
P/s : gospider 被.(jpg|jpeg|gif|css|tif|tiff|png|ttf|woff|woff2|ico)默认列入黑名单
gospider -s "https://www.ddosi.org/" -o output -c 10 -d 1 --blacklist ".(woff|pdf)"显示和黑名单文件长度。
gospider -s "https://www.ddosi.org/" -o output -c 10 -d 1 --length --filter-length "6871,24432" 视频演示
项目地址
GitHub: https://github.com/jaeles-project/gospider
转载请注明出处及链接