
目录导航
JSpector简介
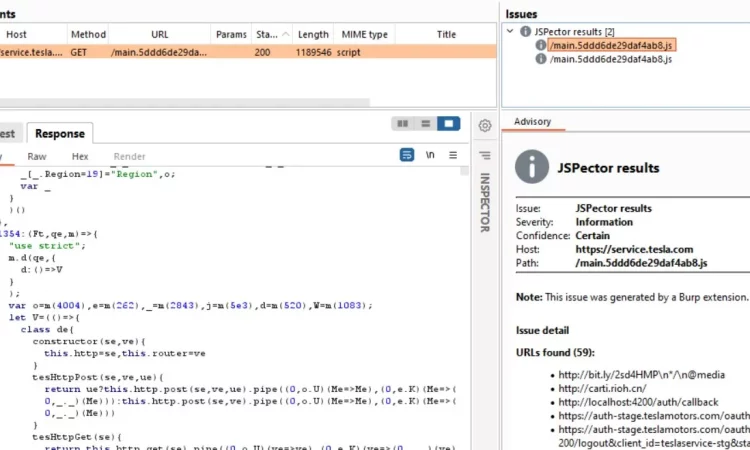
JSpector 是一个 Burp Suite 扩展,它被动地抓取 JavaScript 文件并自动创建在 JS 文件上发现的 URL、端点和危险方法的问题。
先决条件
在安装 JSpector 之前,您需要在 Burp Suite 上安装 Jython。
Jython下载地址
安装
- 下载最新版本的 JSpector
- 打开 Burp Suite 并导航到该
Extensions选项卡。 - 单击选项卡
Add中的按钮Installed。 - 在
Extension Details对话框中,选择Python作为Extension Type。 - 单击该
Select file按钮并导航至JSpector.py. - 单击
Next按钮。 - 一旦输出显示:“JSpector 扩展已成功加载”,请单击按钮
Close。
用法
- 只需浏览您的目标,JSpector 就会在后台开始被动抓取 JS 文件,并自动在选项卡上返回结果。
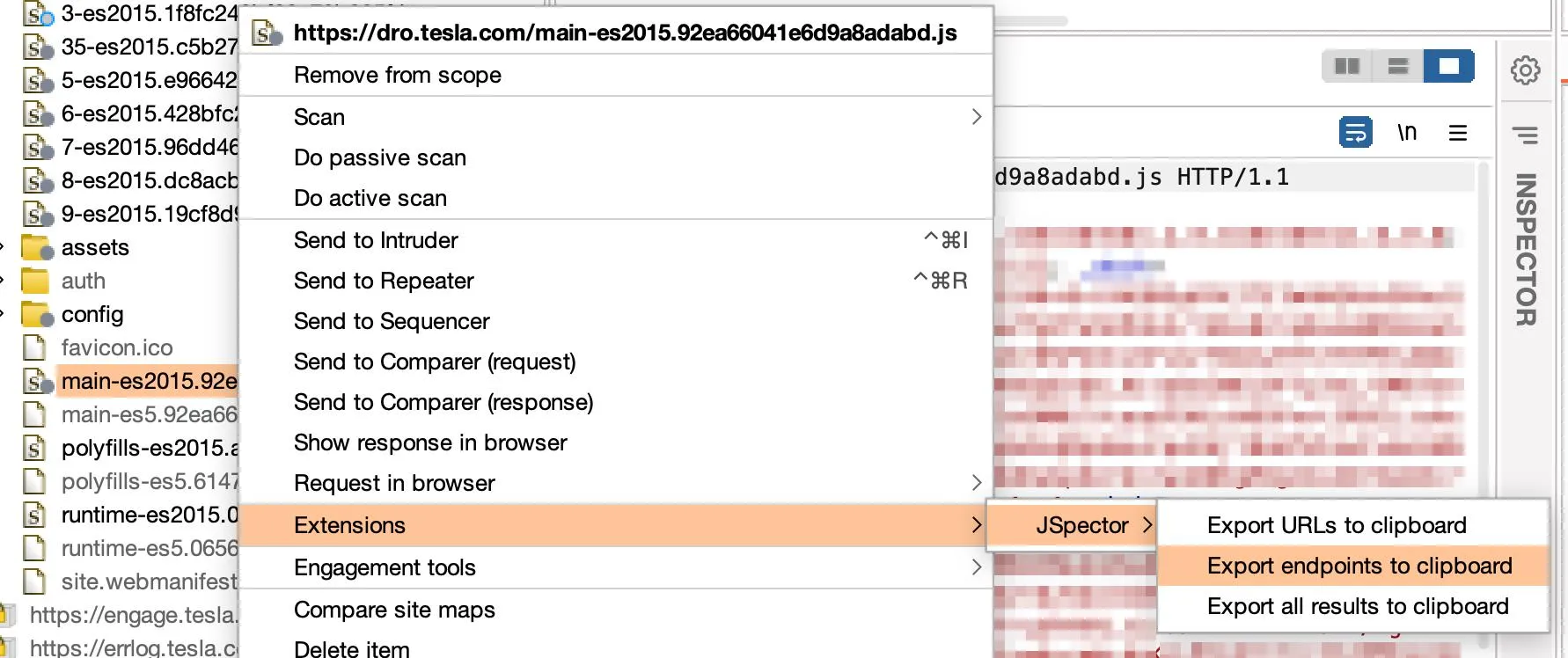
- 您可以通过直接右键单击 JS 文件将所有结果导出到剪贴板(URL、端点和危险方法):
下载地址
不想下载的可直接复制粘贴为JSpector.2.4.8.py文件
from burp import (IBurpExtender, IHttpListener, IScannerListener,
IExtensionStateListener, IContextMenuFactory, IScanIssue)
import re
from java.util import ArrayList
from javax.swing import JMenuItem, JOptionPane
from java.awt import Toolkit
from java.awt.datatransfer import StringSelection
class BurpExtender(IBurpExtender, IHttpListener, IScannerListener, IExtensionStateListener, IContextMenuFactory):
def __init__(self):
self._exclusion_regex = re.compile(r'http://www\.w3\.org')
self._url_pattern = re.compile(r'(?:http|https|ftp|ftps|sftp|file|tftp|telnet|gopher|ldap|ssh)://[^\s"<>]+')
self._endpoint_pattern1 = re.compile(r'(?:(?<=["\'])/(?:[^/"\']+/?)+(?=["\']))')
self._endpoint_pattern2 = re.compile(r'http\.(?:post|get|put|delete|patch)\(["\']((?:[^/"\']+/?)+)["\']')
self._endpoint_pattern3 = re.compile(r'httpClient\.(?:post|get|put|delete|patch)\(this\.configuration\.basePath\+["\']/(?:[^/"\']+/?)+["\']')
self._invocation = None
self._scanned_js_files = set()
def registerExtenderCallbacks(self, callbacks):
self._callbacks = callbacks
self._helpers = callbacks.getHelpers()
callbacks.setExtensionName("JSpector")
callbacks.registerHttpListener(self)
callbacks.registerScannerListener(self)
callbacks.registerExtensionStateListener(self)
callbacks.registerContextMenuFactory(self)
print("JSpector extension loaded successfully.\nWarning: the size of the output console content is limited, we recommend that you save your results in a file.\n")
def processHttpMessage(self, toolFlag, messageIsRequest, messageInfo):
def is_js_file(url):
return url.lower().endswith('.js')
if not messageIsRequest and self._callbacks.isInScope(messageInfo.getUrl()):
js_url = messageInfo.getUrl().toString()
if js_url not in self._scanned_js_files:
self._scanned_js_files.add(js_url)
response = messageInfo.getResponse()
if response:
response_info = self._helpers.analyzeResponse(response)
headers = response_info.getHeaders()
content_type = next((header.split(':', 1)[1].strip() for header in headers if header.lower().startswith('content-type:')), None)
content_type_is_js = content_type and 'javascript' in content_type.lower()
if content_type_is_js or is_js_file(js_url):
body = response[response_info.getBodyOffset():]
urls = self.extract_urls_from_js(body)
if urls:
self.create_issue(messageInfo, urls)
if toolFlag == self._callbacks.TOOL_PROXY:
self._scanned_js_files.add(js_url)
def extract_urls_from_js(self, js_code):
urls = set(re.findall(self._url_pattern, js_code))
endpoints1 = set(re.findall(self._endpoint_pattern1, js_code))
endpoints2 = set(re.findall(self._endpoint_pattern2, js_code))
endpoints3 = set(re.findall(self._endpoint_pattern3, js_code))
urls = set(url for url in urls if not self._exclusion_regex.search(url))
return urls.union(endpoints1, endpoints2, endpoints3)
def create_issue(self, messageInfo, urls):
issue = JSURLsIssue(self._helpers, messageInfo, urls)
self._callbacks.addScanIssue(issue)
js_full_url = messageInfo.getUrl().toString()
self.output_results(urls, js_full_url)
def extensionUnloaded(self):
print("JSpector extension unloaded.")
def newScanIssue(self, issue):
pass
def createMenuItems(self, invocation):
self._invocation = invocation
menu_items = ArrayList()
menu_item1 = JMenuItem("Export URLs to clipboard",
actionPerformed=self.export_urls_to_clipboard)
menu_items.add(menu_item1)
menu_item2 = JMenuItem("Export endpoints to clipboard",
actionPerformed=self.export_endpoints_to_clipboard)
menu_items.add(menu_item2)
menu_item3 = JMenuItem("Export all results to clipboard",
actionPerformed=self.export_results_to_clipboard)
menu_items.add(menu_item3)
return menu_items
def is_js_file(self, url):
return url.lower().endswith('.js')
def export_data_to_clipboard(self, export_type):
messages = self._invocation.getSelectedMessages()
if messages is None:
JOptionPane.showMessageDialog(None, "No JS file selected")
return
all_results = ""
for message in messages:
if self._callbacks.isInScope(message.getUrl()):
js_url = message.getUrl().toString()
if js_url in self._scanned_js_files:
response = message.getResponse()
if response:
response_info = self._helpers.analyzeResponse(response)
headers = response_info.getHeaders()
content_type = next((header.split(':', 1)[1].strip() for header in headers if header.lower().startswith('content-type:')), None)
content_type_is_js = content_type and 'javascript' in content_type.lower()
if content_type_is_js or self.is_js_file(js_url):
body = response[response_info.getBodyOffset():]
urls = self.extract_urls_from_js(body)
if urls:
if export_type == "urls":
urls_list, _ = self.sort_urls_endpoints(urls)
for url in urls_list:
all_results += url + "\n"
elif export_type == "endpoints":
_, endpoints_list = self.sort_urls_endpoints(urls)
for endpoint in endpoints_list:
all_results += endpoint + "\n"
elif export_type == "results":
results = self.format_results(js_url, urls)
all_results += results
return all_results
def export_urls_to_clipboard(self, event):
all_results = self.export_data_to_clipboard("urls")
self.copy_results_to_clipboard(all_results, "URLs")
def export_endpoints_to_clipboard(self, event):
all_results = self.export_data_to_clipboard("endpoints")
self.copy_results_to_clipboard(all_results, "endpoints")
def export_results_to_clipboard(self, event):
all_results = self.export_data_to_clipboard("results")
self.copy_results_to_clipboard(all_results, "results")
def copy_results_to_clipboard(self, all_results, export_type):
if all_results:
num_results = len(all_results.split('\n')) - 1
clipboard = Toolkit.getDefaultToolkit().getSystemClipboard()
clipboard.setContents(StringSelection(all_results), None)
message = "{} {} exported to clipboard".format(num_results, export_type)
JOptionPane.showMessageDialog(None, message)
else:
JOptionPane.showMessageDialog(None, "No results found to export")
def format_results(self, js_full_url, urls):
urls_list, endpoints_list = self.sort_urls_endpoints(urls)
formatted_results = ""
for url in urls_list:
formatted_results += url + "\n"
for endpoint in endpoints_list:
formatted_results += endpoint + "\n"
return formatted_results
def output_results(self, urls, js_full_url):
urls_list, endpoints_list = self.sort_urls_endpoints(urls)
print("JSpector results for {}:".format(js_full_url))
print("-----------------")
print("URLs found ({}):\n-----------------\n{}".format(len(urls_list), '\n'.join(urls_list)))
print("\nEndpoints found ({}):".format(len(endpoints_list)))
if endpoints_list:
print("-----------------\n{}".format('\n'.join(endpoints_list)))
else:
print("No endpoints found.")
print("-----------------")
@staticmethod
def sort_urls_endpoints(urls):
urls_list = []
endpoints_list = []
for url in urls:
if re.match('^(?:http|https|ftp|ftps|sftp|file|tftp|telnet|gopher|ldap|ssh)://', url):
urls_list.append(url)
else:
endpoints_list.append(url)
urls_list.sort()
endpoints_list.sort()
return urls_list, endpoints_list
class JSURLsIssue(IScanIssue):
def __init__(self, helpers, messageInfo, urls):
self._helpers = helpers
self._httpService = messageInfo.getHttpService()
self._url = messageInfo.getUrl()
self._urls = urls
def getUrl(self):
return self._url
def getHttpMessages(self):
return []
def getHttpService(self):
return self._httpService
def getIssueName(self):
return "JSPector results"
def getIssueType(self):
return 0x08000000
def getSeverity(self):
return "Information"
def getConfidence(self):
return "Certain"
def getIssueBackground(self):
return "The following URLs were found in a JavaScript file. This information may be useful for further testing."
def getRemediationBackground(self):
return None
def getIssueDetail(self):
urls_list, endpoints_list = BurpExtender.sort_urls_endpoints(self._urls)
details = self.build_list("URLs found", urls_list)
details += self.build_list("Endpoints found", endpoints_list)
return details
def getRemediationDetail(self):
return None
@staticmethod
def build_list(title, items):
if not items:
return ""
details = "<b>{title} ({num_items}):</b>".format(title=title, num_items=len(items))
details += "<ul>"
for item in items:
details += "<li>{item}</li>".format(item=item)
details += "</ul>"
return details
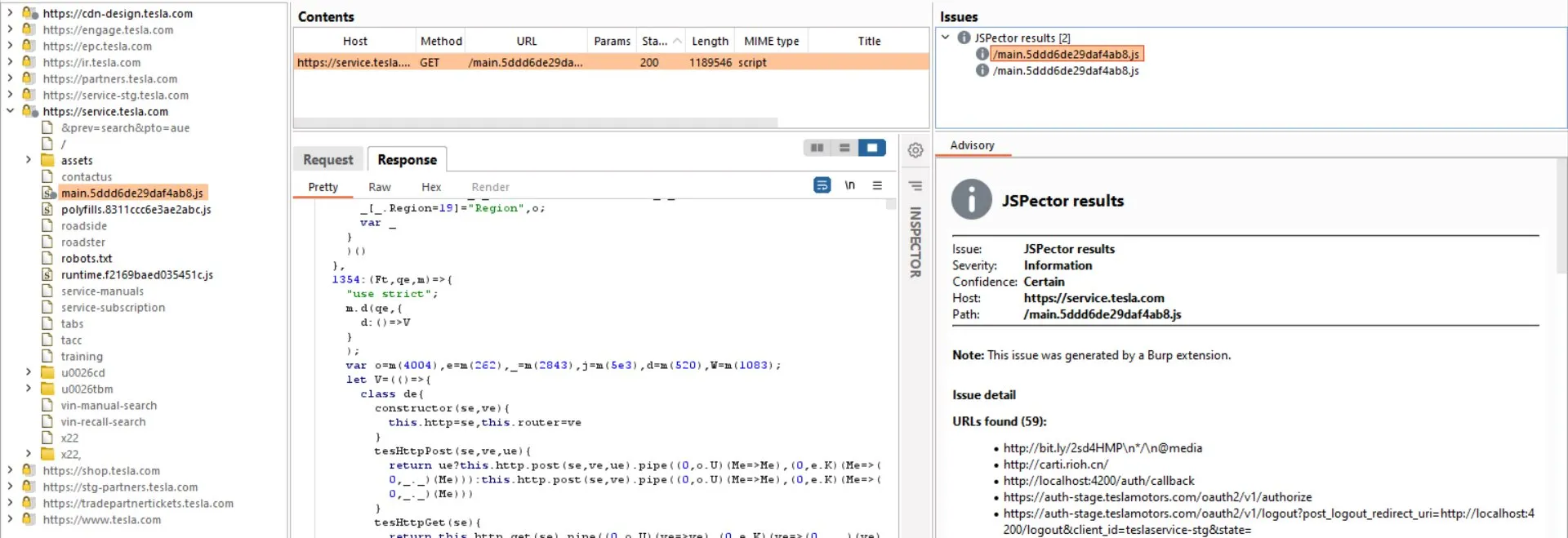
效果图
项目地址
GitHub:
https://github.com/hisxo/JSpector
转载请注明出处及链接