
在文件(通常称为“file”)中搜索匹配项(字符串“hello”)。显示与模式匹配的每一行(在这种情况下,每一行都包含 ‘hello’)
grep hello file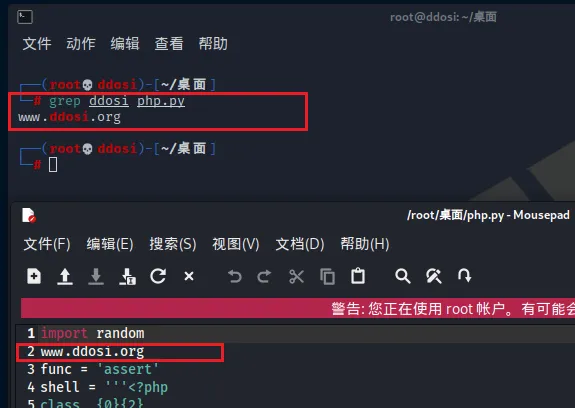
在文件中搜索匹配项并在模式上使用引号。除非您有由 shell 扩展的特殊字符,否则不需要。(在这种情况下不需要)
grep 'hello' file在多个文件中搜索匹配项
grep hello file1 file2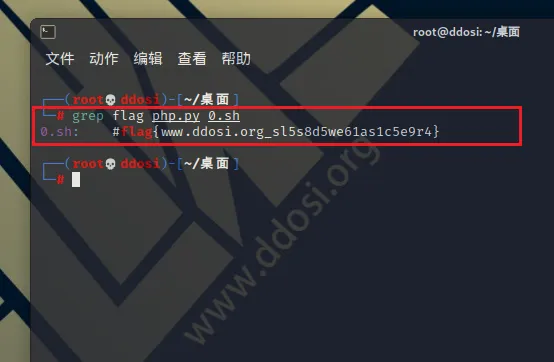
在当前目录中的所有文件中搜索匹配项(如果目录也存在,将显示警告)
grep hello *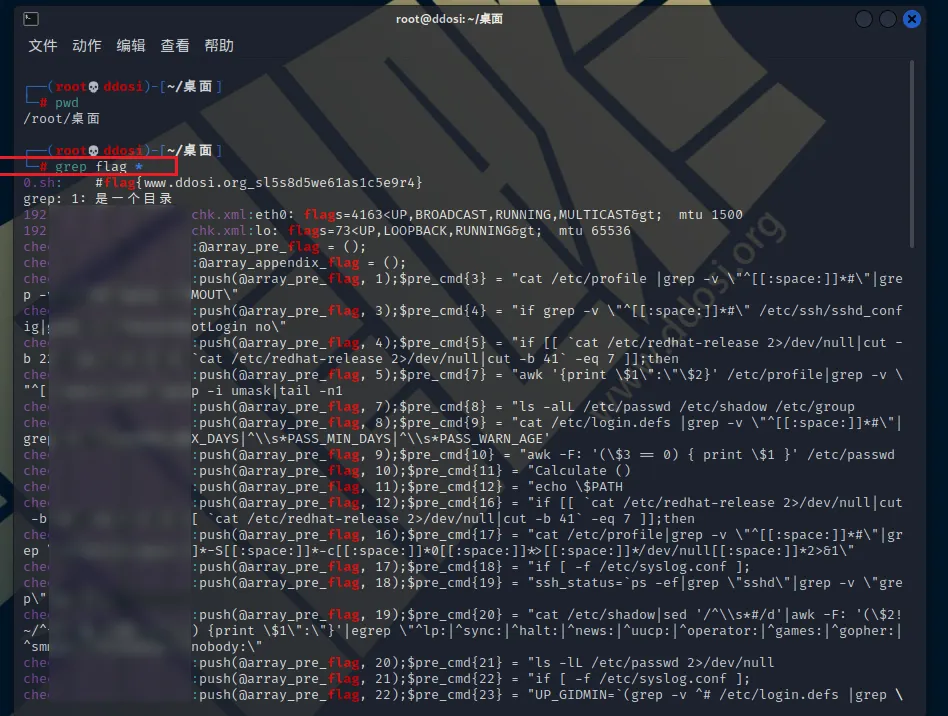
在当前目录中的所有文件中搜索匹配项。如果目录存在,则不要显示错误。(grep 将目录视为普通文件并尝试“读取”它们)。’-s’ 表示静音。还将跳过有关不存在文件的错误。
grep -s hello *在所有以“.py”结尾的文件中搜索匹配项
grep hello *.py在当前目录中的所有文件中搜索匹配项。如果目录存在,则禁止警告。(它在所有文件中搜索 ‘hello’。’skip’ 是传递给 ‘-d’ 的操作)。显示有关不存在文件的警告。
grep -d skip hello *不区分大小写
grep -i Hello file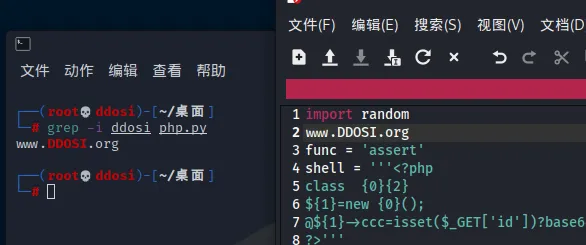
反向搜索
grep -v hello file组合选项。不区分大小写和反转搜索
grep -iv Hello file使用正则表达式。(搜索“Year”或“year”)
grep '[Yy]ear' file使用基本正则表达式(默认)。匹配字符串中的文字 ‘years+’。(’?+{|()’ 没有特殊含义)。不要匹配 ‘years’、’yearss’、’yearsss’ 等。
grep 'years+' file使用扩展正则表达式。匹配“years”、“yearss”、“yearsss”等(“+”表示它前面的一个或多个字符,在本例中为“s”)。’?+{|()’ 有特殊含义。
grep -E 'years+' file同上(扩展正则表达式)
egrep 'years+' file匹配整个单词。将匹配 ‘year’ 但不匹配 ‘goodyear’
grep -w year file匹配整行。将匹配 ‘year’(其中 ‘year’ 是一行中的单个单词。不会匹配 ‘one year’、’goodyear’。
grep -x year file从字面上看搜索模式,而不是正则表达式。将匹配文字 ‘[Yy]ear’ 但不匹配 ‘year’。
grep -F '[Yy]ear' file搜索多个模式。匹配 ‘year’ 和 ‘hello’。
grep -e hello -e year file从文件中读取搜索模式。每个模式在一个新行上。匹配所有找到的模式。’patterns.txt’ 可以在一行中包含 ‘word’,在第二行中包含 ‘[Yy]ear’,等等。
grep -f patterns.txt file从文件和传递给选项“-e”的文本中读取搜索模式。匹配所有找到的模式。
grep -f patterns.txt -e '[Ee]xtra' file计算模式的匹配行数(不匹配模式)。显示一个数字 – 匹配的行数。
grep -c hello file计算除目录之外的每个文件的匹配行数(用“-s”抑制)。显示可能的行如何匹配(对于每个文件)。将显示具有 0 个或多个匹配项的多个文件。
grep -sc hello *仅打印找到匹配项的文件名(不打印实际匹配项)。
grep -l hello *.txt仅打印未找到匹配项的文件名。
grep -L hello *.txt仅在前 N 行中搜索模式。(仅在示例的前 10 行中)
grep -m 10 hello file为当前目录中的每个文件搜索第 N 行的模式。跳过目录。请注意我们如何连接“-m”和“10”。我们也可以用空格来写它们,比如’-m 10′
grep -sm10 hello *只打印匹配的部分,不打印周围的文本。示例将打印 ‘year’、’Year’、’YEAR’ 等 – 每一个都是一个新行
grep -o [Yy]ear file禁止有关文件不存在的错误消息。
grep -s hello file nonexisting_file在每次匹配之前打印文件名。例如:’file:goodyear’(搜索多个文件时的默认值)。
grep -H year file在每次匹配之前禁止打印文件名(即使搜索多个文件)
grep -h year file file2在每个输出行之前添加行号(例如:’1:goodyear’)
grep -n year file打印行号和文件名(例如:’file:3:goodyear’)。’-H’ 将强制显示文件名,即使只有一个文件(默认情况下不显示)。’-s’ 抑制目录丢失警告。
grep -nHs year *在匹配的行之后打印 N 个尾随行。(在匹配的行之后显示 N 行)
grep -A 2 year file同时在匹配行之前打印 N 个尾随行。(在匹配的行之前显示 N 行)
grep -B 2 year file在匹配行之前打印 2 行,在匹配行之后打印 4 行。
grep -B2 -A4 hello file同时打印 N 行 BEFORE 和 N 行 AFTER 匹配行(例如:2 之前和 2 之后)
grep -C 2 year file强制处理二进制文件。没有这个你会得到’grep: /usr/bin/pamon: binary file matching’。(在二进制文件中搜索字符串 ‘au’)
grep -a au /usr/bin/pamon排除与此模式匹配的文件。(例如:不要搜索 .py 或 .c 文件)
grep --exclude=.py --exclude=.c year *包含与此模式匹配的文件。与 –exclude 结合使用。(排除所有 .py 文件,然后在搜索中只包含“main.py”)
grep --exclude=*.py --include=main.py year *在目录中递归搜索(尽可能深入,搜索文件)。不要遵循符号链接。没有显示关于搜索目录的警告。
grep -r hello从搜索中排除目录。使用“-r”跳过某些目录时很有用,例如“.git”
grep hello -r --exclude-dir='.git'在目录中递归搜索。如果遇到 simlynk,请按照它并搜索符号链接指向的文件。
grep -R hello在匹配行之前打印总字节数。第一行(来自文件,不匹配的行)的计数为“0”。例如:第 1 行 – ‘0:abc’,第 2 行 ‘4:def’。它显示 4 因为它到目前为止已经计算了 4 个字节(’abc’ + 第一个文件的换行符)
grep -b hello file在可能以“-”字符开头的文件中搜索“hello”。如果没有“–”,将不会搜索像“-myfile”这样的文件。警告 – 在您的目录中有这样一个文件会破坏“正常”grep 功能(例如:grep hello 不会显示文件中的所有“hello”行。原因是当它遇到文件“-x”时,它会将其视为一个选项,因为它扩展通配符)
grep -- hello *Sausage 选项 1. 搜索二进制文件(也是文本,但对二进制文件友好)。打印字节数(或 grep 调用的偏移量),强制文件名,忽略大小写,仅显示匹配项,还显示行数,在此目录中递归搜索。输出就像’hau/f:15:193:hello’
grep -abHionr hello.