
目录导航
描述:
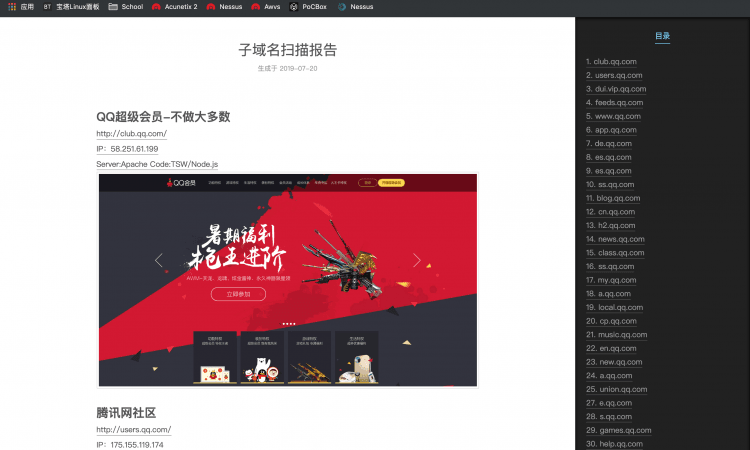
批量探测网站中间件信息 获取网页标题 挂马检查工具bcScan
项目地址:
GitHub:
https://github.com/TheKingOfDuck/bcScan
https://github.com/TheKingOfDuck/domain_screen
存在的问题:
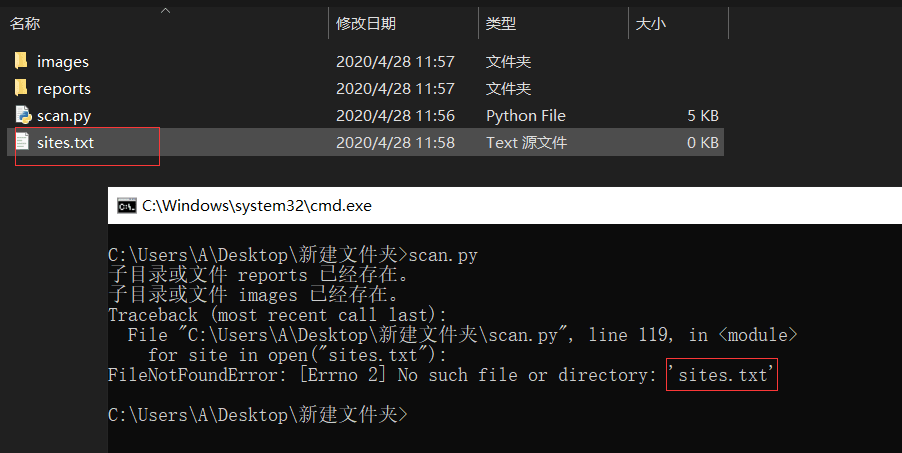
该脚本不会自动生成该sites.txt文件,自己手动创建一个即可
使用方法:
①直接下载scan.py ,安装所需的环境库.
pip install selenium②在sites.txt中写入你需要扫描的网址/ip
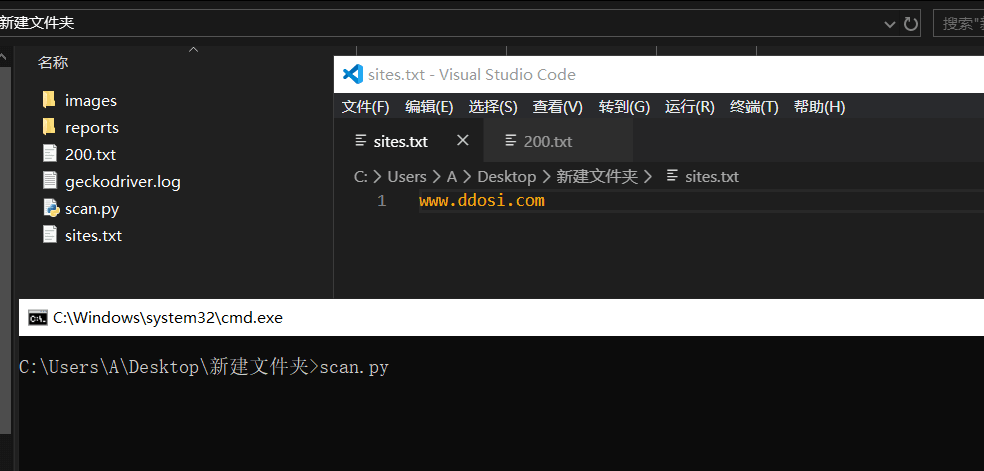
③cmd输入 scan.py回车即可进行扫描.
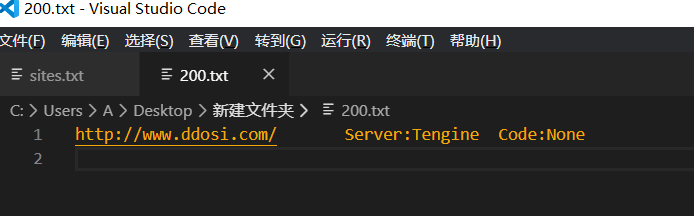
④输出结果在200.txt文件夹中.
另一个是该作者的站点批量截图工具
项目地址
GitHub: https://github.com/TheKingOfDuck/domain_screen
domain_screen
批量采集站点基础信息&截图。
该工具主要用于大量url进行筛选.
精准去除无效的目标.
log
20190726:修复截图过大导致的网络超时问题及简化使用,支持批量截图,截图完的域名列表会直接移到finished目录。(需要截图的域名列表放在根目录下即可)
about
bcScan的升级版本,包括但不限于提升了截图的速度,报告的友好度。
py3环境下运行,报告生成在report目录下。依赖缺啥就自己pip装啥就OK了。
use:
python3 main.py